Временная сложность алгоритмов.
Date: 2015-10-07; view: 512.
Временная сложность (ВС) – зависимость времени выполнения алгоритма от количества обрабатываемых входных данных. Здесь представляет интерес среднее и худшее время выполнения алгоритма. ВС можно установить с различной точностью. Наиболее точной оценкой является аналитическое выражение для функции: t=t(N),где t – время, N – количество входных данных (размерность). Данная функция называется функцией временной сложности (ФВС).
Например: t = 5N2 + 3*2N + 1. Такая оценка может быть сделана только для конкретной реализации алгоритма и на практике обычно не требуется. Часто бывает достаточно определить лишь порядок функции временной сложности t(N).
Две функции f1(N)и f2(N)—одного порядка, если 

Иначе это записывается в виде: f1(N)=О(f2(N)) (Читается " О большое ").
Примеры определения порядка ВС для некоторых алгоритмов:
1) Алгоритм линейного поиска. Этот алгоритм может быть использован как для упорядоченного, так и для неупорядоченного массива ключей. Работа алгоритма заключается в том, что при просмотре всего массива, начиная с первого и до последнего элемента, ключ из массива сравнивается с искомым ключом. Если результат сравнения положительный – ключ найден. Если же ни одно сравнение не выполнилось с положительным результатом, то ключа в массиве нет.
ФВС для алгоритма линейного поиска: t л. п. = k1 * N = O(N). Действительно, для отыскания ключа в худшем случае придется просмотреть все элементы массива. При этом время проверки каждого элемента одинаково и не зависит от конкретной вычислительной системы.
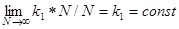
Оценим среднее время алгоритма, при этом будем исходить из следующего: пусть Pi – вероятность того, что будет осуществляться поиск элемента с ключом ki; при этом предположим, что  , т.е. ключ со значением ki не будет отсутствовать (в таблице обязательно есть элемент, поиск которого осуществляется). Среднее время (
, т.е. ключ со значением ki не будет отсутствовать (в таблице обязательно есть элемент, поиск которого осуществляется). Среднее время (  ), как следует из алгоритма, пропорционально среднему числу операций сравнения (
), как следует из алгоритма, пропорционально среднему числу операций сравнения (  ) и равно ~ =
) и равно ~ =  . Если ключи имеют одинаковую вероятность P1=P2=...PN=P, а также учитывая, что
. Если ключи имеют одинаковую вероятность P1=P2=...PN=P, а также учитывая, что  , N*P=1, P=1/N, тогда
, N*P=1, P=1/N, тогда  ,
,
т.е. при линейном поиске в среднем необходимо просмотреть половину массива.
Рассмотрим упорядоченную таблицу, у которой элементы упорядочены по частоте обращений (по вероятности). Если имеем такую таблицу, то время – худшее: = О(N).
Распределение осуществляется по закону Зипфа: Pi = c / i, i = 1, 2, … , N, тогда ~ =  ,
,
причем  ,
,  (N ® ¥)
(N ® ¥)
 , ln N – постоянная Эйлера.
, ln N – постоянная Эйлера.
Исходя из этого получили: с = 1 / ln N.
2) Алгоритм бинарного (двоичного) поиска. В словесной форме алгоритм двоичного поиска можно записать следующим образом:
1. Определить середину массива.
2. Если ключ, находящийся в середине массива, совпадает с искомым, поиск завершен.
3. Если ключ из середины массива больше искомого, применить двоичный поиск к первой половине массива.
4. Если ключ из середины массива меньше искомого, двоичный поиск необходимо применить ко второй половине массива.
5. Пункт 1-4 повторять, пока размер области поиска не уменьшается до нуля. Если это произойдет, то ключа в массиве нет.
ФВС для алгоритма бинарного поиска: t б. п. = O(log 2 N). Это объясняется тем, что на каждом шаге поиска вдвое уменьшается область поиска. До того, как она станет равной одному элементу, произойдет не более log 2 N таких уменьшений, т.е. выполняется не более log 2 N шагов алгоритма.
Изобразим графически функции ВС для линейного и двоичного поиска. Из графика видно, что для малых N нужно использовать линейный поиск, а для большихN —двоичный поиск.Nкр находятся в пределах 10 .. 1000 в зависимости от характеристик используемого оборудования.

СД типа хеш-таблица.
СД типа хеш-таблица использует алгоритм поиска, основанный на идее хеширования. До сих пор, для поиска требуемой записи мы использовали организацию просмотра некоторого количества ключей. Очевидно, что эффективными алгоритмами поиска являются те, которые проходят это количество ключей при минимальном числе сравнений. В идеале хотелось бы иметь такую организацию таблицы, у которой не было бы ненужных сравнений, т.е. чтобы каждый ключ находился за одно сравнение, но в этом случае положение записи в таблице должно зависеть от значения ключа.
| <== previous lecture | | | next lecture ==> |
| СД типа запись (прямое декартово произведение). | | | Операция включения элемента в таблицу. |