Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Точечные и интервальные оценки
Оценка параметра может быть точечной или интервальной. Примером точечной оценки является результат гипотетического выборочного исследования, установившего, что 61 % опрошенных пользователей телефона марки «Brand Name» остались довольны сделанной покупкой, или, что 73% граждан, участвовавших в опросе общественного мнения, поддерживают новые инициативы правительства. Как мы уже говорили, результаты выборочного исследования не могут напрямую переноситься на генеральную совокупность, Т.е. мы не можем сказать, что именно 61 % всех пользователей данной марки телефонов ими довольны, или что точно 73% всех граждан страны поддерживают новый закон. Очевидно, что здесь должен быть некоторый допуск или интервал, в пределах которого можно формулировать результат, например: от 45 до 75 процентов пользователей телефона остались довольны сделанной покупкой, и т.д. Последний подход, безусловно, более оправдан при выборочном исследовании.
Точность интервальной оценки параметра, измеряемого при выборочном исследовании, определяется двумя показателями:
а) интервалом, в котором ожидается обнаружить оцениваемый параметр;
б) вероятностью обнаружения этого параметра в данном интервале.
Эти два показателя объединяет понятие доверительного интервала. Для описания метода нахождения доверительного интервала рассмотрим следующий пример.
Группа студентов университета разрабатывает проект по созданию университетского ланч-клуба «Метро У» (гибрида студенческой столовой и фешенебельного ресторана). Поскольку студенты, помимо фонтана творческих идей и безудержного энтузиазма, имеют еще и достаточно здравого смысла, они решают провести мониторинг ряда параметров, на основании чего и принять решение об организации работы предполагаемого заведения. Предположим, что в качестве измеряемого параметра выступает «Предпочтительное время обеда» .
Допустим, что нам не известны характеристики генеральной совокупности и значения измеряемого параметра. Если бы эти данные были известны, не было бы необходимости проводить выборочное исследование. Как правило, такие данные не доступны, или их получение связано с большими затратами временных, финансовых, технических и др. ресурсов.
Предположим далее, что проведено 4 выборочных измерения (N1, N2, N3, N4). Объем каждой выборки - 10 элементов. Выборки формировались в результате случайного повторного отбора. (Предположение о формировании 4 выборок исследований, а не одной, состоящей, например, из 40 элементов, сделано в учебных целях).

Результаты выборочных исследований представлены в таблице. в данном случае среднее значение измеряемого параметра рассчитывается не как среднее арифметическое (сумма значений признаков объектов, деленное на количество объектов), а как среднее арифметическое взвешенное, поскольку данные сгруппированы.
| Nl | N2 | N3 | N4 | ||
| Х | Время | f | f | f | f |
| 1 | 11:00 | 1 | 1 | О | 1 |
| 2 | 11:30 | 2 | 2 | 1 | 1 |
| 3 | 12:00 | 4 | 5 | 5 | 3 |
| 4 | 12:30 | 2 | 2 | 1 | 4 |
| 5 | 13:00 | 1 | О | 3 | 1 |
| п (объем) | 10 | 10 | 10 | 10 | |
| ХСР (среднее) | 3,0 | 2,8 | 3,6 | 3,3 | |
| s (ст. отклонение) | 1,10 | 0,87 | 1,02 | 1,10 |
Число одинаковых значений признака в ряду распределения называется частотой и обычно обозначается f.
Среднее арифметическое взвешенное определяется по формуле:
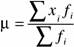 ,
,
а стандартное отклонение взвешенное как

Согласно центральной предельной теореме - одной из основных теорем теории вероятностей и статистики - распределение средних значений выборок, извлекаемых из одной и той же совокупности, при достаточно большом п соответствует нормальному распределению. Среднее значение всех выборочных средних равно среднему значению совокупности, а стандартное отклонение выборочных средних определяется по следующей формуле (предполагается, что выборка формируется в результате случайного повторного отбора).
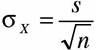
Из этой теоремы следует, что стандартное отклонение по выборке (также используется термин «средняя ошибка выборки») определяет интервал попадания среднего по генеральной совокупности, и ошибка среднего значения по генеральной совокупности зависит от стандартного отклонения и объема выборки.
Естественным образом возникает вопрос о том, какой объем выборки может считаться «большим». Известно эмпирическое правило, согласно которому принимается, что если объем выборки (N)равен 100 или более, то применима центральная предельная теорема, и допущение о нормальности распределения всех возможных выборочных средних может быть принято. Если же Nменьше 100, то нужно иметь веские доказательства нормальности распределения генеральной совокупности, и только в этом случае можно полагать, что распределение, которому подчиняются выборочные статистики, является нормальным. Следовательно, нормальность распределения выборочных статистик гарантируется путем использования довольно больших выборок.
Мы видим, что стандартное отклонение по генеральной совокупности зависит от стандартного отклонения по выборке и ее объема. Например, если стандартное отклонение по выборке s=0,74 и n=10, то стандартное отклонение по генеральной совокупности равно
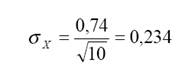
Если стандартное отклонение по выборке уменьшается в два раза, то оцениваемое изменение по генеральной совокупности также уменьшается в два раза:
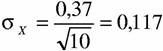
Предположим, что по результатам выборочного исследования мы получаем оценку изменения измеряемого параметра как
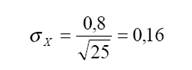
При увеличении количества респондентов в 4 раза, при том же самом значении стандартного отклонения по выборке, мы можем обеспечить увеличение точности в 2 раза:
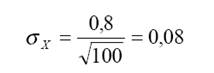
При бесповторном случайном отборе ошибка выборки рассчитывается как
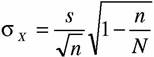
Очевидно, что для применения этой формулы (и этого механизма отбора соответственно) нам должна быть известна численность генеральной совокупности N.
При нормальном распределении данных большая их часть (68,27%) располагается в пределах одного стандартного отклонения (z=l) по обе стороны от среднего значения, вне зависимости от величины стандартного отклонения (что следует из закона нормального распределения случайной величины). Это означает, что с вероятностью 0,68 среднее значение параметра по генеральной совокупности будет попадать в интервал:
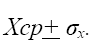
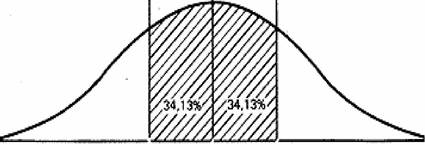
В пределах трех стандартных отклонений (z=3) умещается почти вся генеральная совокупность - 99,73%. Это означает, что с вероятностью >0,99 среднее значение параметра по генеральной совокупности будет попадать в интервал
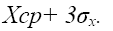 .
.
Зная формулу, описывающую закон нормального распределения, можно определить значения z, которые соответствуют различным значениям вероятности попадания среднего значения параметра по генеральной совокупности в интервал 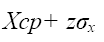 (см. таблицу).
(см. таблицу).
| z | Площадь покрытия, % | Вероятность попадания в интервал, % |
| 1,00 | 68,27 | 68,27 |
| 1,65 | 90,10 | 90,10 |
| 1,96 | 95,00 | 95,00 |
| 3,00 | 99,73 | >99 |
Определяя стандартное отклонение выборочных средних по характеристикам первой выборки в нашем примере, получим

(Для сравнения: стандартное отклонение средних, рассчитанное как среднее арифметическое по 4 выборкам  .
.
Т
аким образом, по результатам первого выборочного обследования мы можем оценить интервал изменения среднего по генеральной совокупности: ±0,35 (12:00±10,5 мин)
При этом вероятность попадания среднего по генеральной совокупности в этот интервал равна 68%, Т.к. мы принимаем z=l. Аналогично, с вероятностью 95% по характеристикам первой выборки можно утверждать, что интервал изменения среднего по генеральной совокупности:
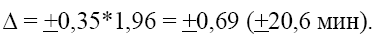
Теперь мы можем сделать содержательный вывод о необходимом объеме выборки. Для определения необходимого количества элементов в выборке мы должны задать доверительный интервал, который включает в себя:
- интервал, в котором ожидается обнаружить оцениваемый параметр,
- вероятность, с которой ожидается обнаружить оцениваемый параметр в определенном интервале.
Доверительный интервал определяется как
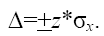
| <== предыдущая страница | | | следующая страница ==> |
| Статистическая достоверность связи и статистическая гипотеза | | | Введение. ОАО «СПЕЦМАГНИТ» — разработчик и производитель постоянных магнитов и магнитных элементов и систем на основе этих магнитов для электроники |
Дата добавления: 2015-07-26; просмотров: 234; Нарушение авторских прав

Мы поможем в написании ваших работ!