Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
ВИЗНАЧЕННЯ НАДМІРНОСТІ ПОВІДОМЛЕНЬ. ОПТИМАЛЬНЕ КОДУВАННЯ
Якщо ентропія джерела повідомлень не дорівнює максимальній ентропії для алфавіту з|із| даною кількістю якісних ознак (маються на увазі якісні ознаки алфавіту, за допомогою яких складаються повідомлення), то це перш за все|передусім| означає, що повідомлення даного джерела могли б нести більшу кількість інформації. Абсолютна недогруженность| на символ повідомлень такого джерела

Для визначення кількості «зайвої» інформації, яка закладена в структурі алфавіту або в природі коду, вводиться поняття надмірності. Надмірність, з якою ми маємо справу в теорії інформації, не залежить від змісту повідомлення і зазвичай заздалегідь відома із статистичних даних[4]. Інформаційна надмірність показує відносну недогруженность на символ алфавіту і є безрозмірною величиною:
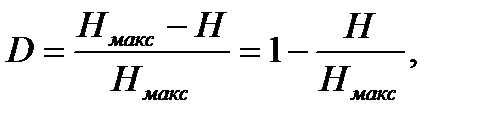 (29)
(29)
де  — коефіцієнт ущільнення|стиснення| (відносна ентропія), Н та Ні обчислюються щодо|відносно| одного і того ж алфавіту.
— коефіцієнт ущільнення|стиснення| (відносна ентропія), Н та Ні обчислюються щодо|відносно| одного і того ж алфавіту.
Окрім|крім| загального|спільного| поняття надмірності існують частинні види надмірності.
Надмірність, обумовлена нерівноймовірним розподілом символів в повідомленні
 (30)
(30)
Надмірність, викликана|спричиняти| статистичним зв'язком між символами| повідомлення
 (31)
(31)
Повна|цілковита| інформаційна надмірність
 (32)
(32)
Надмірність, яку отримують в результаті|унаслідок| нерівномірного розподілу в повідомленнях якісних ознак цього коду, закладається в природі цього коду і не може бути задана числом на підставі статистичних випробувань.
Так при передачі десяткових цифр двійковим кодом максимально завантаженими бувають тільки|лише| ті символи вторинного|повторного| алфавіту, які передають значення, що є|з'являються| цілочисельними ступенями|мірами| двійки. У решті випадків тією ж кількістю символів може бути передане|передавати| більша кількість цифр (повідомлень). Наприклад, трьома двійковими розрядами ми можемо передати|передавати| і цифру 5, і цифру 8, тобто на передачу п'яти повідомлень витрачається стільки ж символів, скільки витрачається і на вісім повідомлень.
Фактично для передачі повідомлення досить мати довжину кодової комбінації
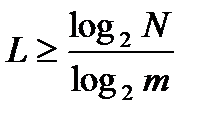 ,
,
де N - загальна кількість передаваних повідомлень.
L можна представити і як
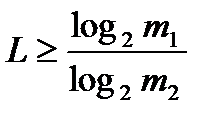 ,
,
де і —соответственно| якісні ознаки первинного і вторинного|повторного| алфавітів. Тому для цифри 5 в двійковому коді можна записати
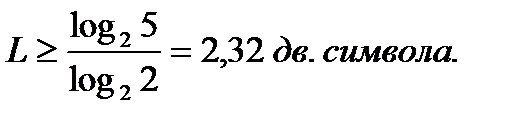
Проте|однак| цю цифру необхідно округляти|округлювати| до найближчого цілого числа, оскільки|тому що| довжина коди не може бути виражена|виказувати| дробовим числом. Округлення, природно, проводиться у велику сторону. У загальному|спільному| випадку, надмірність від округлення

де к - закруглене до найближчого цілого числа значення. Для нашого прикладу|зразка|

Надмірність - не завжди небажане явище. Для підвищення перешкодостійкості код надмірність необхідна і її вводять штучно у вигляді додаткових 
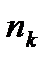 символів. Якщо в коді всього n розрядів і
символів. Якщо в коді всього n розрядів і 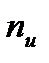 з них несуть інформаційне навантаження, то =
з них несуть інформаційне навантаження, то = 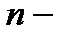
 характеризує абсолютну надмірність, що коректує, а величина
характеризує абсолютну надмірність, що коректує, а величина  характеризує відносну надмірність, що коректує.
характеризує відносну надмірність, що коректує.
Інформаційна надмірність - звичайне явище природне, закладена вона в первинному алфавіті. Надмірність, що коректує, - явище штучне, закладена вона в кодах,представлених у вторинному алфавіті.
Найбільш ефективним способом зменшення надмірності повідомлення є|з'являється| побудова|шикування| оптимальних кодів.
Оптимальні коди [5]- коди з практично нульовою надмірністю. Оптимальні коди мають мінімальну середню довжину кодових слів - L. Верхня і нижня межі L визначаються з нерівності
 (33)
(33)
де Н - ентропія первинного алфавіту, m - число якісних ознак вторинного алфавіту.
У разі поблочного кодування, де кожен з блоків складається з М незалежних букв  мінімальна середня довжина кодового блоку лежить в межах
мінімальна середня довжина кодового блоку лежить в межах

Загальний|спільний| вираз|вираження| середнього числа елементарних символів на букву|літеру| повідомлення при блоковому|блочному| кодуванні

З погляду інформаційного навантаження на символ повідомлення поблочне кодування завжди вигідніше, ніж побуквенное|.
Суть блокового|блочного| кодування можна з'ясувати на прикладі|зразку| представлення десяткових цифр в двійковому коді. Так, при передачі цифри 9 в двійковому коді необхідно витратити 4 символи, тобто 1001. Для передачі цифри 99 при побуквенном| кодуванні - 8, при поблочному - 7, оскільки|тому що| 7 двійкових знаків достатні для передачі будь-якої цифри від 0 до 123; при передачі цифри 999 співвідношення буде 12 - 10, при передачі цифри 9999 співвідношення буде 16 - 13 і так далі В загальному|спільному| випадку «вигода» блокового|блочного| кодування виходить і за рахунок того, що в блоках відбувається|походить| вирівнювання вірогідності|ймовірності| окремих символів, що веде до підвищення інформаційного навантаження на символ.
При побудові|шикуванні| оптимальних кодів найбільше розповсюдження|поширення| знайшли методики Шенона - Фано і Хаффмена.
Згідно|згідно з| методиці Шенона - Фано побудова|шикування| оптимального коду ансамблю з|із| повідомлень зводиться до наступного|слідуючої|:
1-й крок. Множина|безліч| з|із| повідомлень розташовується в порядку убування вірогідності|ймовірності|.
2-й крок. Первинний|початковий| ансамбль кодованих сигналів розбивається на дві групи так, щоб сумарна вірогідність|ймовірність| повідомлень обох груп була по можливості рівна. Якщо рівній імовірності в підгрупах не можна досягти, то їх ділять так, щоб у верхній частині|частці| (верхній підгрупі) залишалися символи, сумарна вірогідність|ймовірність| яких менше сумарної вірогідності|ймовірності| символів в нижній частині|частці| (у нижній підгрупі).
3-й крок. Першій групі привласнюється символ 0, другій групі символ 1.
4-й крок. Кожну з освічених підгруп ділять на дві частини|частки| так, щоб сумарна вірогідність|ймовірність| знов|знову| освічених підгруп була по можливості рівна.
5-й крок. Першим групам кожною з підгруп знов|знову| привласнюється 0, а другим - 1. Таким чином, ми отримуємо|одержуємо| другі цифри коду. Потім кожна з чотирьох груп знов|знову| ділиться на рівні (з погляду сумарної вірогідності|ймовірності|) частини до тих пір, поки в кожній з підгруп не залишиться по одній букві|літері|.
Згідно методиці Хаффмена, для побудови оптимального коду  символів первинного алфавіту виписуються в порядку спадання вірогідності. Останні
символів первинного алфавіту виписуються в порядку спадання вірогідності. Останні 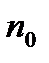
( 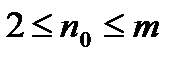 [6] ,
[6] ,  - ціле число) символів об'єднують в деякий новий символ з вірогідністю, рівній сумі ймовірностей об'єднаних символів. Останні символи з урахуванням утвореного символу знову об'єднують і отримують новий, допоміжний символ, знову виписують символи в порядку убування ймовірності з урахуванням допоміжного символу і так далі до тих пір, поки сума ймовірностей символів, що залишилися, після -го виписування в порядку убування ймовірностіне дасть в сумі вірогідність, рівну 1. На практиці зазвичай, не проводять багатократного виписування ймовірностей символів з урахуванням ймовірності допоміжного символу, а обходяться елементарними геометричними побудовами, суть яких зводиться до того, що символи кодованого алфавіту попарно об'єднуються в нові символи, починаючи з символів, що мають найменшу вірогідність. Потім з урахуванням знов освічених символів, яким привласнюється значення сумарної ймовірностідва попередніх, будують кодове дерево, у вершині якого коштує символ з вірогідністю 1. При цьому відпадає необхідність у впорядковуванні символів кодованого алфавіту в порядку убування вірогідності.
- ціле число) символів об'єднують в деякий новий символ з вірогідністю, рівній сумі ймовірностей об'єднаних символів. Останні символи з урахуванням утвореного символу знову об'єднують і отримують новий, допоміжний символ, знову виписують символи в порядку убування ймовірності з урахуванням допоміжного символу і так далі до тих пір, поки сума ймовірностей символів, що залишилися, після -го виписування в порядку убування ймовірностіне дасть в сумі вірогідність, рівну 1. На практиці зазвичай, не проводять багатократного виписування ймовірностей символів з урахуванням ймовірності допоміжного символу, а обходяться елементарними геометричними побудовами, суть яких зводиться до того, що символи кодованого алфавіту попарно об'єднуються в нові символи, починаючи з символів, що мають найменшу вірогідність. Потім з урахуванням знов освічених символів, яким привласнюється значення сумарної ймовірностідва попередніх, будують кодове дерево, у вершині якого коштує символ з вірогідністю 1. При цьому відпадає необхідність у впорядковуванні символів кодованого алфавіту в порядку убування вірогідності.
Побудовані|спорудити| за вказаними вище (або подібними) методиками коди з|із| нерівномірним розподілом символів, що мають мінімальну середню довжину кодового слова, називають оптимальним нерівномірним кодами (ОНК). Рівномірні коди можуть бути оптимальними тільки|лише| для передачі повідомлень з|із| рівноймовірним розподілом символів первинного алфавіту, при цьому число символів первинного алфавіту має дорівнювати цілому ступеню|мірі| числа, рівного кількості якісних ознак вторинного|повторного| алфавіту, а у разі|в разі| двійкових код - цілого ступеня|міри| два.
Максимально ефективними будуть ті ОНК, у|біля| яких

Для двійкових кодів
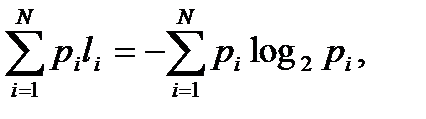 (36)
(36)
оскільки log22 = 1. Очевидно, що рівність (36) задовольняється за умови, що довжина коду у вторинному алфавіті

Величина 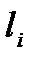 точно рівна Н, якщо
точно рівна Н, якщо  де п - будь-яке ціле число. Якщо n не є цілим числом для всіх значень букв первинного алфавіту, то
де п - будь-яке ціле число. Якщо n не є цілим числом для всіх значень букв первинного алфавіту, то  і, згідно основній теоремі кодування[7], середня довжина кодового слова наближається до ентропії джерела повідомлень у міру укрупнення кодованих блоків.
і, згідно основній теоремі кодування[7], середня довжина кодового слова наближається до ентропії джерела повідомлень у міру укрупнення кодованих блоків.
Ефективність ОНК оцінюють за допомогою коефіцієнта статистичного ущільнення|стиснення|:
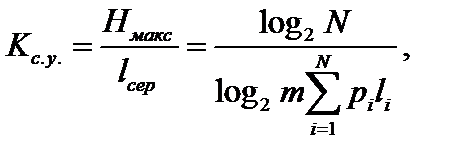 (37)
(37)
який характеризує зменшення кількості двійкових знаків на символ повідомлення при застосуванні|вживанні| ОНК в порівнянні із застосуванням|вживанням| методів нестатистичного кодування і коефіцієнта відносної ефективності
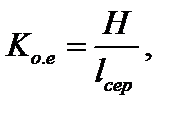 (38)
(38)
який показує, наскільки використовується статистична надмірність передаваного повідомлення.
Для найбільш загального|спільного| випадку нерівноімовірних і взаимонезависимых| символів

Для випадку нерівноімовірних і взаємозалежних символів
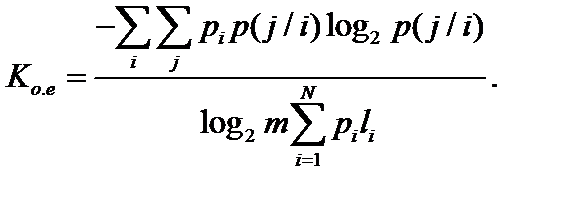
Завдання 4.1 : Повідомлення складається з алфавіту а, b, з, d. Ймовірність появи букв алфавіту в текстах рівна відповідно:  Знайти надмірність повідомлень, складених з даного алфавіту.
Знайти надмірність повідомлень, складених з даного алфавіту.
Розв’язок:
Надмірність, згідно (29)
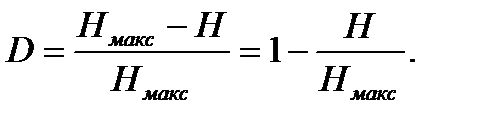
Для алфавіту з|із| чотирьох букв|літер| максимальна ентропія
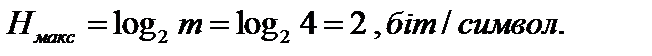
Середня ентропія на символ повідомлення

Тоді надмірність

Завдання 4.2: Побудувати оптимальний код повідомлення, в якому ймовірність появи букв первинного алфавіту, що складається з 8 символів, є цілим від’ємним ступенем двійки, а 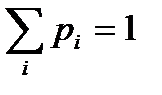 .
.
Рішення: Побудова оптимального коду ведеться за методикою Шеннона-фано. Результати побудови відбіті в таблиці:
| Буква | Імовірність появи букви | Кодове слово | Число знаків в кодовому слові | 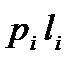
|
| А1 А2 А3 А4 А5 А6 А7 А8 | 1/4 1/4 1/8 1/8 1/16 1/16 1/16 1/16 | 0,5 0,5 0,375 0,375 0,25 0,25 0,25 0,25 |
Перевірка:

Примітка|тлумачення|. Кодові слова з однаковою ймовірностю|ймовірності| появи мають рівну довжину.
| <== предыдущая страница | | | следующая страница ==> |
| Подготовка к запуску | | | Поняття про ідею корекції помилок |
Дата добавления: 2015-07-26; просмотров: 862; Нарушение авторских прав

Мы поможем в написании ваших работ!