Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Автомат с магазинной памятью
Грамматический разбор цепочки символов для КС-грамматики сводится к построению дерева порождения (или левого канонического разбора) для этой цепочки. Для осуществления такого разбора будем использовать алгоритм распознавания, называемый автоматом с магазинной памятью (МПА). Также как КА, он прочитывает входную цепочку слева направо. В отличие от КА, МПА содержит дополнительную память, работающую по принципу магазина (стека).
Автомат с магазинной памятью задается семеркой множеств:
{Σ, Q, q0, F, Γ, Z0, δ},
где Σ – множество (алфавит) входных символов; Q – множество состояний МПА; q0 – начальное состояние, 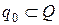 ; F – множество заключительных состояний,
; F – множество заключительных состояний, 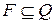 ; Γ – множество (алфавит) магазинных символов; Z0 – начальный магазинный символ,
; Γ – множество (алфавит) магазинных символов; Z0 – начальный магазинный символ, 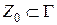 ; δ – множество правил перехода.
; δ – множество правил перехода.
Действие каждого из правил перехода определяется входным символом, верхним символом магазина и текущим состоянием МПА. Действие может содержать в различных сочетаниях такие шаги: а) удаление из магазина верхнего символа, б) запись в магазин нескольких символов, в) переход к чтению следующего входного символа, г) изменение текущего состояния. Так, запись правила перехода в виде:
(a, B, qi) → (λ, γB, qj),
где 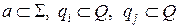 , а символ B и символы из цепочки γ все принадлежат алфавиту Γ, означает, что в магазин, содержащий верхний символ B, записывается цепочка символов γ, текущее состояние становится qj , после чего делается переход к чтению следующего входного символа. Правило:
, а символ B и символы из цепочки γ все принадлежат алфавиту Γ, означает, что в магазин, содержащий верхний символ B, записывается цепочка символов γ, текущее состояние становится qj , после чего делается переход к чтению следующего входного символа. Правило:
(a, B, qi) → (a, λ, qj),
означает, что из магазина удаляется верхний символ B, текущее состояние становится qj , переход к чтению следующего входного символа не производится.
До начала функционирования МПА в магазине имеется начальный магазинный символ, МПА находится в начальном состоянии. На каждом шаге работы читается очередной символ входной цепочки, начиная с первого, читается верхний символ магазина, и выполняются действия по такому правилу перехода, которое соответствует этим символам и текущему состоянию. Работа МПА заканчивается, когда не будет ни одного подходящего правила, чтобы можно было продолжать работу. Если при этом выполнены три условия: цепочка прочитана вся, магазин пуст, МПА находится в заключительном состоянии, то цепочка считается распознанной. Если же хотя бы одно из этих условий нарушено, цепочка считается нераспознанной. Цепочка считается нераспознанной и в том случае, если МПА никак не может остановиться, т.е. когда он зациклил, и нет продвижения по входной цепочке.
МПА будет детерминированным (ДМПА), если на каждом шаге возможно применение не более одного правила перехода. Если же на каком-либо шаге можно выполнить действия по двум или более правилам перехода, то МПА будет недетерминированным (НМПА), тогда он должен выполнять действия в соответствии со всеми этими правилами параллельно. Гипотетически такое одновременное выполнение нескольких переходов можно представить так: Создаются копии МПА в количестве, соответствующем количеству одновременно выполняемых правил, после чего каждая копия независимо от других выполняет действия по своему правилу. Некоторые из копий могут попадать в тупики, их работа заканчивается, но это не влияет на работу других копий. Если, в конце концов, хотя бы одна из копий распознает входную цепочку, то считается, что входная цепочка распознана недетерминированным МПА. Входная цепочка считается нераспознанной, если ни одна из копий МПА не распознала цепочку. Таким образом, НМПА проверяет все возможные варианты действий на каждом шаге работы. Следует заметить, что количество всех работающих копий может оказаться таким большим, что превысит любое наперед заданное число, поэтому функционирование НМПА можно представить чисто гипотетически.
При грамматическом разборе дерево порождения может строиться двумя основными способами: сверху вниз и снизу вверх. В обоих случаях входная цепочка символов читается слева направо. При разборе сверху вниз вначале строится корень дерева – начальный нетерминал. Затем, в соответствии с левым каноническим порождением, подбираются такие порождающие правила, чтобы, в конце концов, висячие вершины дерева совпали с символами входной цепочки. Такой вариант разбора называют LL-разбором (от англ. left – левый), так как цепочка символов читается слева направо, а дерево строится, как при левом каноническом порождении.
При разборе снизу вверх дерево строится снизу – начиная от символов входной цепочки. При этом, в соответствии с порождающими правилами на очередных шагах производится сворачивание – переход от правой части правила к нетерминалу левой части. Полностью дерево получается на самом последнем шаге, когда в нем будет построен корень. Здесь мы не будем рассматривать алгоритмы разбора снизу вверх, хотя они тоже используются на практике.
| <== предыдущая страница | | | следующая страница ==> |
| Дерево порождения для КС-грамматики | | | LL-разбор КС-грамматики автоматом с магазинной памятью |
Дата добавления: 2015-07-26; просмотров: 163; Нарушение авторских прав

Мы поможем в написании ваших работ!