Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Лекция 4. Обзор важнейших методов статистического анализа
Обзор важнейших методов статистического анализа
4.1 Корреляционный анализ
Корреляция — это статистическая зависимость между случайными величинами, не имеющая строго функционального характера. В рамках корреляции величин изменение одной из них приводит к изменению математического ожидания другой. Поэтому связь между величинами проявляется лишь в изменении средних величин результативного признака.
Факторные (независимые) признаки — это признаки, которые изменяются независимо от других признаков. Результативные (зависимые) признаки — это такие, величина которых обусловлена изменением факторных признаков.
Однако в реальных задачах могут встречаться независимо изменяющиеся признаки, для которых трудно (или вообще нельзя) определить какой из них является факторным, а какой – результирующим.
Обычно корреляционный анализ имеет целью определение наличия (или отсутствия наличия) и силы связей между значениями параметров. В литературе встречаются и иные определения, например "Корреляционный анализ— метод, используемый для измерения степени близости взаимосвязи между двумя или более сопоставимыми по интервалу переменными".
Обычно различают следующие варианты корреляций между признаками:
• парная — связь между двумя признаками (при этом обычно не требуется определять, какой из них факторный, а какой результативный);
• частная — зависимость между результативным и одним факторным признаком (или наоборот) при фиксированных значениях других факторных признаков;
• множественная — зависимость результативного признака от двух или более факторных признаков, учитываемых в исследовании.
На практике в основном используется парный корреляционный анализ, причем оцениваются только "линейные взаимосвязи" между параметрами.
Различают корреляционный анализ:
- по Пирсону (обычный, он наиболее распространен);
- ранговый.
Коэффициент корреляции (КК) по Пирсону можно вычислять, только если значения во всех парах значений параметров представлены количественными показателями. В случае пропуска одного из значений в "паре" (отсутствие данных) эта пара исключается из корреляционного анализа.
Для парного КК по Пирсону диапазон изменения КК составляет от "-1" до "+1", а сам метод анализа может применяться, когда все значения признаков в обоих рядах (для которых и оценивается КК) выражены в количественной форме.
При этом:
- значение "+1" соответствует строго прямо пропорциональной зависимости признаков;
- значение "-1" соответствует строго "обратно пропорциональной зависимости" признаков;
- значение "0" соответствует случаю, когда значения в рядах меняются совершенно независимо друг от друга.
Формула для оценки парного КК по Пирсону имеется во всех руководствах по статистическому анализу. Кроме того, ее можно посмотреть в справке MsExcel.
Помимо самой величины КК обычно оценивается ее "значимость" (по определенному уровню значимости), т.е. вероятность того, что вычисленному КК можно доверять с вероятностью не ниже заданной (соответственно уровню значимости). Такая процедура оценки связана с тем, что значения величин в рядах обычно случайный характер (по крайней мере частично) и, следовательно, высокое значение коэффициента корреляции также может носить случайный характер.
Таким образом, оценка "достоверности" КК может производиться при разных уровнях значимости. Понятно, что при малом числе пар значений в сравниваемых рядах, "достоверность" значения КК может быть невысокой – даже если сам КК достаточно большой. Подробности методов оценки "значимости" КК описаны в литературе для данного модуля.
Коэффициент корреляции рангов применяется тогда, когда один или оба параметра нельзя выразить в количественной форме, но можно установить их места в рядах (т.е. ранжировать по порядку) исходя из тех или иных критериев предпочтительности. Возможна также и экспертная оценка мест в рядах (например, при оценке собак по качеству экстерьера на соответствующих соревнованиях). Коэффициент корреляции рангов может определяться по той же формуле, что КК по Пирсону (и следовательно его значения лежат в интервале от -1 до +1).
Однако в руководствах по статистическому анализу более часто используется "ранговый коэффициент корреляции по Спирмену" (для тех же целей, что и коэффициент корреляции рангов).
Его значения могут изменяться от "0" до "+1". При этом:
- нулевое значение рангового КК соответствует отсутствию корреляционной связи;
- значение "+1" – строго функциональной взаимосвязи.
Для рангового КК также имеются процедуры оценки значимости (аналогично КК по Пирсону).
Большинство основных компьютерных пакетов статистического анализа ориентированы на вычисление не "одиночных" КК (т.е. между рядами двух параметров), а на построение корреляционных матриц, включающих значение КК между большим количеством рядов значений. При этом корреляционные матрицы позволяют выявить пары факторов (или группы факторов) достаточно тесно связанные друг с другом.
В функциональном отношении корреляционный анализ используется при выработке управленческих, технических и других типов решений в случаях, когда зависимости между переменными носят статистический (вероятностный) характер. Он позволяет, например, оценить, насколько можно доверять прогнозной оценке зависимого параметра, при изменениях влияющего (факторного) признака.
4.2 Регрессионный анализ
Регрессионный анализ заключается в построении аналитических выражений, в которых изменение одной величины (называемой зависимой или результативным признаком) обусловлено изменением одной или нескольких независимых величин (факторов). При этом для множества всех прочих факторов принимаются постоянные значения.
Регрессионный анализ может использоваться и для аналитических и для прогнозных целей.
Подчеркнем, что вид зависимости (аналитического выражения) для регрессионного анализа может в общем случае выбираться различным образом. Однако, произвольный выбор зависимости обычно не допустим, т.к. она может не соответствовать теоретическим представлениям о зависимости между результативной и независимой переменными. На практике для регрессионных уравнений (РУ) обычно стараются подобрать уравнение минимальной сложности, т.к. для них проще содержательная интерпретация.
Зависимость между переменными в рамках регрессионного анализа носит статистический характер. При этом "сила связи" между переменными в рамках выбранного типа зависимости (включая и нелинейные) может оцениваться по разному. Обычно для этой цели используют R^2 фактор или корреляционное отношение.
Как правило, для РУ существует диапазон значений независимой переменной (переменных) при котором использование РУ является адекватным.
По направлению связи в простейшем случае принято различать регрессию:
• прямую (положительную), которой соответствует ситуация "если растет независимая величина, то растет и зависимая величина);
• обратную (отрицательную), соответствует ситуации, когда "с увеличением или уменьшением независимой величины зависимая величина соответственно уменьшается или увеличивается" (т.е. они изменяются в разных направлениях).
Однако в общем случае РУ могут описывать и более сложные зависимости, включая изменения типа зависимости (с положительной на отрицательную и наоборот) в пределах диапазона адекватности использования РУ.
Регрессионный анализ широко применяется при принятии различных видов управленческих решений, когда исследуются (и прогнозируются) взаимосвязи двух и более переменных. Подчеркнем, что регрессионный анализ опирается на экспериментальные данные. Эти данные могут быть получены путем натурного, лабораторного или даже вычислительного эксперимента, а также путем "пассивного" наблюдения (без вмешательства в ход происходящих процессов).
Обычно регрессионный анализ в отношении оценки зависимостей и поддержки принятия решений является более простой альтернативой имитационному компьютерному моделированию.
4.3 Понятие о дисперсионном анализе
Основной целью дисперсионного анализа является оценка силы влияния "организованных" влияющих факторов на результирующий показатель. Под организованными понимаются факторы, значениями которых в рамках эксперимента можно управлять. Помимо них обычно существуют и неорганизованные факторы, значениями которых управлять нельзя (это "неучтенные" факторы, значения которых в эксперименте носят случайный характер). При этом для выбранных сочетаний организованных факторов (или, по крайней мере, для большей части таких сочетаний) требуется проведение "повторных" (многократных) опытов – для оценки дисперсии воспроизводимости (результирующий показатель может изменяться в силу воздействия "неорганизованных" или не учтенных факторов при одних и тех же сочетаниях "организованных" факторов).
Таким образом, дисперсионный анализ относится к обработке результатов спланированных экспериментов, в которых можно управлять значениями хотя бы части (в минимальном варианте – одного) из факторов.
Источниками данных для дисперсионного анализа могут быть натурные эксперименты, лабораторные эксперименты, вычислительные эксперименты.
Дисперсионный анализ – это отдельное направление исследований. В рамках дисперсионного анализа не решаются вопросы определения вида зависимости (это сфера регрессионного анализа) или оценки коэффициентов корреляции (это сфера корреляционного анализа).
Количественно оценка силы влияния факторов в рамках дисперсионного анализа обычно выражается в процентах. При этом сумма влияний всех факторов (организованных и неорганизованных) составляет 100%. Поэтому сила влияния одного из организованных факторов (или группы организованных факторов) никогда не может превышать 100%.
Принято различать "однофакторный" дисперсионный анализ, "двухфакторный" и более.
Отметим, что уже трехфакторный дисперсионный анализ применяется редко, т.к. требует проведения достаточно большого количества опытов, особенно если количество "градаций" по каждому организованному фактору - значительно). В связи с этим повторим, что в рамках дисперсионного анализа для каждого значения (или большей части значений) организованного фактора (в случае одномерного дисперсионного анализа) или сочетания организованных факторов (для "двухфакторного" и более) могут проводиться повторные эксперименты (при этом их результаты обычно различаются в силу влияния неорганизованных факторов).
Расчетные формулы для оценки результатов дисперсионного анализа имеются в соответствующих руководствах (см литературу для данного модуля).
Некоторые возможности дисперсионного анализа имеются и в MsExcel, особенно если установлена надстройка "пакет анализа".
4.4 Основные понятия кластерного анализа
При разработке управленческих решений, а также при проведении ситуационного анализа, может быть эффективным применение кластерного анализа. Его целью, обычно, является группировка объектов в "кластеры" (группы) по совокупностям их характеристик (реже - по тому или иному признаку). Такая группа в определенном смысле может рассматриваться как "единое целое".
Экономисты иногда говорят не об "отраслях экономики", а о "кластерах экономики", подразумевая под этим: "собственно отрасль" и то, что "связано с ней". В том числе могут рассматриваться "региональные кластеры", например "транспортная отрасль в регионе".
В качестве другого примера кластера можно привести "отрасль + вузы, подготавливающие специалистов по данной отрасли + смежные отрасли, обеспечивающие деятельность рассматриваемой отрасли + группы потребителей продукции отрасли и др.).
С позиций управления объединение близких (или взаимосвязанных по своим функциям) структур (организаций) в "общий кластер" (в техническом отношении это может быть, например, холдинг) позволяет достигнуть:
• повышения производительности труда;
• оптимизации внутренних финансовых потоков и отказа от внешних кредитных заимствований;
• снижения объема циркулирующей внутри кластера информации и оптимизации информационных потоков;
• улучшения координации деятельности организаций внутри кластера.
Такое "экономическое" понимание термина "кластер" конечно, отличается от традиционного понимания кластера в области математической статистики.
В техническом отношении традиционный кластерный анализ (как метод математической статистики) представляет собой совокупность алгоритмов (часть из них являются альтернативными), позволяющих объединить в подгруппы совокупность элементов. Каждый из элементов характеризуется набором параметров.
Как правило, эти параметры выражены в количественной форме. Тогда каждый из элементов характеризуется многомерным вектором значений, представляющим собой набор чисел, определяющих его компоненты (эти компоненты могут рассматриваться как координаты элемента в многомерном пространстве).
Однако возможны и только качественные характеристики элементов в виде:
- "0" - признак не характерен для данного элемента,
- "1" - признак присущ данному элементу.
Таким образом, каждый элемент будет представлять собой многомерный вектор, состоящий из "0" и "1", что позволяет свести задачу к ранее рассмотренной.
Группировка элементов в кластеры осуществляется исходя из многомерных расстояний между ними. При этом важно отметить следующее.
А) Как правило, в качестве предварительного этапа кластерного анализа осуществляется сначала "нормирование" значений показателей (например, нормированием на среднее значение каждого показателя). Тем самым выполняется переход от размерных значений показателей к безразмерным, что позволяет корректно оперировать ими совместно.
Б) Вычисление многомерных расстояний между элементами возможно в рамках:
- эвклидовой метрики (т.е. расстояние отсчитывается по наикратчайшей линии, соединяющей точки в многомерном пространстве);
- манхэттеновской метрики (т.е. как сумма расстояний между точками по каждой из многомерных координат).
Подчеркнем еще раз, что существуют различные алгоритмы объединения точек (агрегирования). В основном применяются алгоритмы, в которых:
- сначала задается "каждая точка – в виде отдельного кластера";
- затем начинают последовательно (по одной паре) объединяться близкие кластеры (на каждом шаге – одна наиболее близкая пара) – при этом в каждом из двух объединяемых кластеров может быть как одна "точка", так и несколько "точек";
- процесс заканчивается, когда количество кластеров становится равным заданному значению (это значение должно задаваться исследователем – из самой задачи оно обычно не следует).
Отметим, что достаточно наглядное отображение того, как объединены объекты в рамках кластеров, возможно только при двух параметрах, по которым осуществляется кластеризация (т.е. можно показать объединение точек в кластеры на плоскости).
Методы кластерного анализа присутствуют в большинстве современных статистических пакетов программ. Обычно в них процесс последовательного объединения объектов (элементов) в кластеры показывается в виде так называемой дендрограммы.
4.5 Методы факторного анализа.
Факторный анализ- это процедура установления силы влияния факторов на функцию или результативный признак (обычно с целью ранжирования факторов для разработки плана организационно-технических мероприятий по улучшению функции).
Обычно факторный анализ решает задачи определения:
• номенклатуры факторов, необходимых для выявления всех существенных зависимостей, влияющих на развитие ситуации или процесса;
• коэффициентов (называемых иногда нагрузками), характеризующих силу влияния каждого из выявленных факторов на показатели, отражающие состояние и развитие ситуации (процесса).
Применение методов факторного анализа обычно позволяет на основе определенных методов обработки статистической информации разделить факторы на существенные и несущественные (основные и не основные). Это, в свою очередь, облегчает (и делает более объективным) принятие решений на основе имеющихся данных.
По результатам обработки статистических данных с использованием методов факторного анализа может устанавливаться необходимость и производиться детализация факторов либо, наоборот, может устанавливаться необходимость и производиться "укрупнение" факторов,
т.е. объединение исходных (натуральных) факторов в группы.
На практике методы факторного анализа обычно используются именно для группировки факторов, относительно тесно связанных друг с другом (это оценивается через корреляционные матрицы). При этом часто говорят о "снижении размерности пространства показателей".
Обычно, принято различать следующие методы факторного анализа:
- метод главных компонент (их количество всегда равно количеству исходных параметров);
- метод главных факторов (их количество меньше количества исходных параметров).
При этом метод "главных компонент" является "начальным этапом" метода главных факторов. В последнем возможны различные подварианты, отличающиеся используемым методом "вращения" факторов для перераспределения факторных нагрузок (Целью перераспределения нагрузок является стремление добиться того, чтобы большая часть дисперсии исходных данных приходилась на первые несколько главных факторов. Тогда остальные факторы можно будет с относительно небольшой погрешностью не принимать во внимание). При этом, в методе главных факторов обычно заранее неизвестно какой из вариантов вращения факторов даст лучшие результаты. Как правило, отсутствует и "идеологическое обоснование" предпочтительности выбора какого-то определенного варианта вращения.
В методах главных компонент и главных факторов фактически используются некоторые "синтетические" показатели, построенные в виде линейных комбинаций значений исходных (натуральных) показателей. Весовые коэффициенты при исходных показателях как раз и являются нагрузками факторов, определяющими "силу влияния" этих показателей на значение главной компоненты или главного фактора.
В обоих случаях (методы главных компонент и главных факторов) содержательная интерпретация указанных выше синтетических показателей затруднена. Обычно им дают названия, соответствующие одному-двум параметрам, для которых весовые коэффициенты имеют наибольшую абсолютную величину (в рамках данной главной компоненты или главного фактора), т.е. эти параметры влияют сильнее всего. При этом такие названия носят "не стандартизованный" характер, т.е. могут меняться от задачи к задаче.
Рассчитанные на основании рассматриваемых в данном разделе методов коэффициенты влияния каждого из выделенных факторов (факторные нагрузки) позволяют:
• определить ранжирование факторов по важности, т.е. расположить факторы в порядке убывания их важности (в рамках данной компоненты или данного главного фактора);
• оценивать предполагаемые значения "синтетических" показателей на основании произвольных (но в разумном диапазоне) значений исходных параметров.
Таким образом, в рамках процедур поддержки принятия решений методы данного раздела могут быть полезны только когда необходимо принимать решения зависящие от большого числа взаимосвязанных факторов.
4.6 Методы дискриминантного анализа
Дискриминантный анализ применяется, как правило, к объектам, описываемым совокупностями значений переменных, а не одной переменной.
Считается, что дискриминантный анализ позволяет проверить гипотезу о непротиворечивости предполагаемой классификации заданного множества n объектов на k классов в m-мерном пространстве переменных Хj, где j=1-m.
Однако основной задачей дискриминантного анализа является классификация новых объектов, т.е. отнесение их по совокупности значений параметров к тому или иному классу.
В ходе вычислений в рамках дискриминантного анализа ищется набор дискриминирующих функций  , обеспечивающий классификацию объектов на заданное число
, обеспечивающий классификацию объектов на заданное число 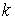 классов.
классов.
 ; (
; (  ) (4.1)
) (4.1)
Для отнесения объекта к классу его многомерные подставляются в дискриминирующие функции всех классов. Та функция, для которой будет иметь максимальное значение, и будет определять класс, к к которому следует отнести объект.
На практике в силу наличия "случайностей" в исходных данных возникают ошибки "дискриминации". Они могут быть двух родов:
- объект, попал в нужный класс, хотя объективно он должен был бы быть отнесен к другому классу;
- объект не попал в нужный класс, хотя объективно он к нему относится.
Одним из вариантов практического применения дискриминантного анализа в сфере информационных технологий может быть автоматизированный биометрический контроль доступа физических лиц по их отпечаткам пальцев.
В настоящее время такой контроль осуществляется:
- при доступе в помещения (мини сканер папиллярных узоров + база данных для лиц, которым разрешен доступ);
- как способ санкционирования работы с флэш-накопителями некоторых типов, снабженных средством считывания папиллярных узоров и запоминания единственного узора, для которого разрешен доступ).
Отметим, что на практике в таких системах количество ошибок и первого и второго рода может быть достаточно большим. Поэтому системы биометрического контроля по папиллярным узорам в ряде случаев считаются пока недостаточно надежными, что приводит к необходимости их дублирования другими методами.
4.7 Методы шкалирования
Отметим, что в различных руководствах по статистическому анализу понимание идеологии и содержания этих методов может несколько отличаться.
Во многих областях деятельности часто затруднительно или невозможно произвести непосредственное измерение переменных, характеризующих изучаемый объект (процесс), а можно лишь тем или иным образом (включая экспертное оценивание) определить взаимную близость или же различия между парами объектов. В то же время для детального анализа (в т.ч. и с использованием рассмотренных ранее методов) желательно оперировать именно с числовыми переменными, характеризующими каждый объект индивидуально.
Задачей метода шкалирования является построение метрического пространства небольшой размерности, в которое может быть погружен многомерный граф, узлы которого составляют объекты, а длины ребер пропорциональны расстояниям между объектами.
В общем случае шкалирование может быть одномерным (по одному параметру) и многомерным (по двум и более параметрам).
Принято различать:
- метрическое шкалирование (по методу Торгерсона);
- неметрическое шкалирование (методы Шепарда-Крускала, Говера.
В случае неметрического шкалирования необходимо указать размерность пространства шкалирования и выбрать метрику или метод вычисления расстояний между объектами (в этих методах кроме ранее рассмотренных "эвклидовой" и "манхэттеновской" используются еще метрики по "Колмогорову" и "Минковскому".
Основная задача многомерного шкалированиясостоит в том, чтобы уменьшить число факторов, которые необходимо принимать во внимание при анализе и оценке ожидаемых изменений ситуации. в результате тех или иных решений, в т.ч. управленческих (отказ руководства оргаизации от вмешательства в ситуацию, т.е. от управляющего воздействия также является одним из вариантов управленческого решения).
При использовании метода многомерного шкалирования факторы, действительно определяющие развитие ситуации (процесса), могут быть неизвестны. Они устанавливаются в процессе применения метода путем "отбора" из имеющейся номенклатуры факторов. Математические основы этих методов описаны в специальных руководствах, а сами методы включены в наиболее популярные компьютерные пакеты статистического анализа.
Каждый, таким образом выделенный фактор получает со стороны специалистов, участвующих в проведении ситуационного анализа, содержательную интерпретацию.
Считается, что использование метода многомерного шкалирования эффективно помогает установлению наиболее существенных факторов, определяющих развитие ситуации (процесса).
| <== предыдущая страница | | | следующая страница ==> |
| Лекция 3. Обзор основных математических методов, используемых при анализе информации и принятии решений | | | Понятия прогноза и прогнозирования |
Дата добавления: 2015-07-26; просмотров: 102; Нарушение авторских прав

Мы поможем в написании ваших работ!