Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Тема 11. Теория автоматов
План лекции:
1. Понятие автомата. Типы автоматов
2. Формальное определение автомата
1. Понятие автомата. Типы автоматов
Автомат - это алгоритм, определяющий некоторое множество и, возможно, преобразующий его в другое множество. Неформальное описание автоматов выглядит следующим образом: автомат имеет входную ленту, управляющее устройство с конечной памятью для хранения номера состояния, а также может иметь вспомогательную (рабочую) и выходную ленты.
Существует два типа автоматов:
1) распознаватели - автоматы без выхода, которые распознают, принадлежит ли входная цепочка заданному множеству L;
2) преобразователи - автоматы с выходом, которые преобразуют входную цепочку x в цепочку y при условии, что x ∈ L.
Входную ленту можно рассматривать как линейную последовательность ячеек, причем каждая ячейка может хранить один символ из некоторого конечного входного алфавита.
Лента автомата бесконечна, но занято на ней в каждый момент времени только конечное число ячеек. Граничные слева и справа от занятой области ячейки могут заниматьспециальные концевые маркеры. Маркер может стоять только на одном конце ленты или может отсутствовать вообще.
Входная головка в каждый момент времени читает (обозревает) одну ячейку входной ленты. За один такт работы автомата входная головка может сдвинуться на одну ячейку вправо или остаться на месте, при этом она выполняет только чтение, т.е. в ходе работы автомата символы в ячейках входной ленты не меняются.
Рабочая лента - это вспомогательное хранилище информации. Данные с нее могут читаться автоматом, могут и записываться на нее.
Управляющее устройство - это программа, управляющая поведением автомата. Оно представляет собой конечное множество состояний вместе с отображением, описывающим, как меняются состояния в соответствии с текущим входным символом, читаемым входной головкой, и текущей информацией, извлеченной с рабочей ленты. Управляющее устройство также определяет направление сдвига рабочей головки и то, какую информацию записать на рабочую ленту.
Автомат работает, выполняя некоторую последовательность рабочих тактов. В начале такта читается входной символ и исследуется информация на рабочей ленте. Затем, в зависимости от прочитанной информации и текущего состояния, определяются действия автомата:
1) входная головка сдвигается вправо или стоит на месте;
2) на рабочую ленту записывается некоторая информация;
3) изменяется состояние управляющего устройства;
4) на выходную ленту (если она есть) записывается символ.
Поведение автомата удобно описывать в терминах конфигурации автомата, которая включает в себя:
а) состояние управляющего устройства;
б) содержимое входной ленты с положением входной головки;
в) содержимое рабочей ленты вместе с положением рабочей головки;
г) содержимое выходной ленты, если она есть.
Управляющее устройство может быть недетерминированным. В таком случае для каждой конфигурации существует конечное множество возможных следующих тактов, любой из которых автомат может сделать, исходя из этой конфигурации. Управляющее устройство будет детерминированным, если для каждой конфигурации будет возможен только один следующий такт.
Существуют следующие типы автоматов:
1) машина Тьюринга (МТ);
2) линейно-ограниченный автомат (ЛОА);
3) автомат с магазинной памятью (МП-автомат);
4) конечный автомат (КА).
Сложность рабочей ленты определяет сложность автомата. Так, например:
1) машина Тьюринга имеет неограниченную в обе стороны ленту;
2) у линейно-ограниченного автомата длина рабочей ленты представляет собой линейную функцию длины входной цепочки;
3) у МП-автомата рабочая лента работает по принципу магазина LIFO;
4) у конечного автомата рабочая лента отсутствует.
2.Формальное определение автомата
Неинициальный автомат - это пятерка вида А = (К, X, Y, δ, γ), где
К - множество состояний (алфавит состояний);
Х - входной алфавит;
Y - выходной алфавит;
δ - функция переходов, задающая отображение К⋅Х→К;
γ - функция выходов, задающая отображение К⋅Х→У.
Функционирование автомата можно задать множеством команд вида qx → py, где q и p Î K, x Î X, y Î Y.
Пусть на некотором такте ti управляющее устройство находится в состоянии q, а из входной ленты читается символ x. Если в множестве команд есть команда qx → py, то на такте ti на выходную ленту записывается символ y, а к следующему такту ti+1 управляющее устройство перейдет в состояние p, т.е.:
y(t) = γ(q(t), x(t)), q(t+1) =δ(q(t), x(t)).
Если же команда qx → py отсутствует, то автомат оказывается блокированным и не реагирует на символ, принятый в момент ti, а также перестает воспринимать символы в последующие моменты времени.
В соответствии с определением неинициального автомата в начальный момент состояние автомата может быть произвольным.
Если зафиксировано некоторое начальное состояние, то такой автомат называют инициальным, т.е. q(0) = q0.
Инициальный автомат - это шестерка вида А = (К, X, Y, δ, γ, q0), где
К - множество состояний (алфавит состояний);
Х - входной алфавит;
Y - выходной алфавит;
δ - функция переходов (отображение К ⋅ Х → К);
γ - функция выходов (отображение К ⋅ Х → У);
q0 - начальное состояние.
Тема 12. Языки и автоматы
План леции
1.. Распознаватели. Языки и автоматы
2. Автоматы с магазинной памятью
Задача грамматического разбора заключается в нахождении вывода цепочки в заданной грамматике и определения дерева вывода этой цепочки.
Языки могут быть заданы двумя способами:
1) грамматиками (порождающее средство языка);
2) автоматами (распознающее средство языка).
Различным по сложности автоматам соответствуют разные типы языков. Простейшим типом автоматов являются конечные автоматы.
Конечный автомат имеет входную ленту, с которой за один такт может быть считан один входной символ. Возврат по входной ленте не допускается.
Конечным автоматом называется пятерка вида А = (К, ∑, δ, p0, F), где
К - конечное множество состояний;
∑ - алфавит;
δ - функция переходов;
p0 - начальное состояние;
F - множество заключительных состояний.
Автомат можно определить как формальную систему через состояния, через символы, которые пишутся (читаются) с ленты или с нескольких лент, и через набор команд.
Конечный автомат можно представить графом, таблицей переходов, командами, а также матрицей переходов.
Регулярные множества
Регулярные множества образуют класс языков, имеющих важное значение для теории формальных языков. Рассмотрим несколько методов задания языков, каждый из которых определяет регулярные множества. Среди них - регулярные выражения, праволинейные грамматики, детерминированные и недетерминированные конечные автоматы.
Пусть Σ - некоторый алфавит. Регулярное множество в алфавите Σ определяется рекурсивно следующим образом:
1) 0 - пустое множество;
2) {ε} - множество из пустой цепочки;
3) {a} - регулярное множество для каждого элемента a Î Σ;
4) если P и Q - регулярные множества в алфавите Σ, то регулярными являются
множества:
а) P È Q
б) PQ
в) P*.
Других регулярных множеств в алфавите Σ нет. Таким образом, некоторое множество цепочек в заданном алфавите Σ называется регулярным тогда и только тогда, когда либо оно является одним из множеств: 0, {ε} или {a} для некоторого a Î Σ, либо его можно получить из этих множеств применением конечного числа операций объединения, конкатенации и итерации.
Для каждого регулярного множества существует по крайней мере одно регулярное выражение, обозначающее это множество.
Язык, распознаваемый конечным автоматом, - это множество цепочек, читаемых автоматом при переходе из начального состояния в одно из заключительных состояний:
L(A)={a1 a2 ... an | p0a1 → p1, p1a2 → p2, ..., pn-1an → pn; pn Î F}.
Множество называется регулярным, если существует конечный детерминированный автомат, распознающий его.
Операции над регулярными языками
Так как произвольному конечному автомату однозначно соответствует детерминированный конечный автомат, операции над конечными автоматами эквивалентны операциям над регулярными множествами, или регулярными языками.
Известно, что для произвольного конечного автомата можно построить эквивалентный автомат без циклов в начальных и (или) конечных состояниях.
Теорема. Для произвольного конечного автомата существует конечный автомат без циклов в начальном состоянии.
Доказательство. Пусть A = (К, ∑, δ, p0, F) - произвольный конечный автомат. Построим автомат:
A1 = (K È {q0}, Σ, δ È {q0a → pi | p0a → pi Î δ}, q0, F È {q0 | p0 Î F}).
Любая цепочка x = a1 a2 ... ak принадлежит языку L(A) тогда и только тогда, когда существует следующая последовательность команд автомата А:
p0a1 → p1; p1a2 → p2; . . . ; ph-1ah → ph, ph Î F
и соответствующая ей последовательность команд автомата А1:
q0a1 → p1; p1a2 → p2; . . . ; pk-1ak → ph.
Таким образом, имеем: A = A1.
Теорема. Для произвольного конечного автомата существует эквивалентный автомат без циклов в заключительном состоянии.
Доказательство. Будем считать, что автомат не имеет циклов в начальном состоянии.
Сопоставим заданному произвольному конечному автомату A = (К, ∑, δ, p0, F) новый автомат A1:
A1 = (KÈ {f}, Σ, δÈ {qja → f | pja → piÎδ & piÎF}, p0, {f}È {p0 | p0 Î F}).
В результате имеем: A = A1.
Теорема. Множество регулярных языков замкнуто относительно операций итерации, усеченной итерации, объединения, произведения, пересечения, дополнения и разности.
Доказательство. Для доказательства необходимо выполнить операции над соответствующими конечными автоматами и показать, что в результате таких преобразований построенный автомат допускает требуемый язык. Предполагается, что в автомате удалены циклы из начальных и заключительных состояний. Для выполнения перечисленных в теореме операций необходимо выполнить соответствующие преобразования над заданными автоматами.
1. Операция итерации реализуется удалением циклов из начальных и заключительных состояний и объединения полученных состояний. Объединение начального и заключительного состояний означает, что построенный автомат допускает пустую цепочку.
Однократный переход из начального в заключительное состояние исходного автомата соответствует допуску цепочек языка L. Поскольку эти состояния объединены, автомат допускает цепочки языков LL, LLL и т.д., т.е. он распознает язык {ε}ÈLÈL2È . . . =L*.
2. Операция произведения над L(A1) и L(A2) выполняется с помощью двух преобразований: а) удаляются циклы из начального состояния A2 и заключительного состояния A1; б) каждому заключительному состоянию A1 ставим в соответствие свой экземпляр A2 и объединяем заключительные состояния A1 с начальным состоянием соответствующего экземпляра A2.
3. Объединение L(A1) и L(A2) строится с помощью удаления циклов в начальных состояниях A1 и A2 и объединения полученных начальных состояний.
4. Усеченная итерация может быть построена двумя способами:
а) L(A1)+= L(A1)* L(A1),
б) L(A1)+= L(A1) L(A1)*.
5. Рассмотрим дополнение L(A1) до Σ*. Пусть автомат A1 детерминированный, тогда любая цепочка x=a1a2 . . an распознается по единственному маршруту:
p0a1 → p1
p1a2 → p2
. . .
pn-1an → pn, pnÎ F.
Автомат не распознает только те цепочки, которые:
1) либо представляют собой начальную часть цепочки a1a2 . . aj, при чтении которой автомат переходит в состояние, не являющееся заключительным;
2) либо имеют вид y = a1a2 . . akbc1c2 . . cm (k < n), где начало цепочки a1a2 . . ak совпадает с началом цепочки xÎL(A1), но за символом ak стоит такой символ b, что автомат A1 его прочитать не может.
Поэтому для того чтобы построить автомат, распознающий дополнение языка, необходимо:
а) все заключительные состояния сделать незаключительными, а незаключительные состояния - заключительными;
б) ввести дополнительное состояние, сделать его заключительным и из каждого состояния провести в это состояние такие дуги, каждая из которых соответствует символам алфавита, не читаемым в этом состоянии;
в) в построенном дополнительном состоянии построить петли для всех символов алфавита, чтобы обеспечить чтение произвольного окончания цепочки c1c2 . . cm.
6. Разность L(A1) и L(A2) строится в соответствии со следующим преобразованием:
L(A1) \ L(A2) = L(A1) ∩ L(A2) .
7. Операция пересечения строится в соответствии со следующим преобразованием:
L(A1) ∩ L(A2) = L(A1) È L(A2) .
На основании этой теоремы можно строить конечные автоматы, последовательно синтезируя их на основе уже построенных автоматов.
Автоматные грамматики
Линейные грамматики (праворекурсивные и леворекурсивные) называются автоматными грамматиками, так как языки, порождаемые ими, совпадают с языками, распознаваемыми конечными автоматами.
Рассмотрим ряд теорем.
Теорема. Для каждой праволинейной грамматики существует эквивалентный конечный автомат.
Доказательство. Каждому нетерминалу произвольной праволинейной грамматики G поставим в соответствие одно состояние конечного автомата A. Добавим еще одно состояние - единственное конечное состояние. Состояние, соответствующее аксиоме, назовем начальным состоянием.
Каждому правилу A→aB поставим в соответствие команду Aa → B, а каждому терминальному правилу A → a поставим в соответствие команду Aa → F.
Таким образом, выводу цепочки в грамматике
S Þ a1A1 Þ a1a2A2 Þ ...Þ a1a2...ak-1Ak-1Þ a1a2...ak взаимно однозначно соответствует последовательность команд построенного автомата A:
Aa1 → A1; A1a2 → A2; . . . ; Ak-1ak → F. Таким образом, язык L(G) = L(A).
Пример. Пусть для заданной грамматики G требуется построить конечный автомат.
S → aS | bB;
A → aA | bS;
B → bB | с | cA.
Решение. Граф автомата будет иметь четыре вершины, три из них помечены нетерминальными символами грамматики S, A, B, четвертая вершина, помеченная символом F, является единственным заключительным состоянием. Начальным состоянием является вершина, соответствующая аксиоме S.
 a b
a b
 S b B
S b B



b
c
c
 A F
A F
 a
a
Каждому правилу грамматики поставим в соответствие команду конечного автомата:
Sa → S - в начальном состоянии при поступлении на вход терминального символа а автомат остается в том же состоянии S;
Sb → B - из начального состояния при поступлении на вход терминала b автомат переходит в состояние B;
Bb → B - в состоянии В при поступлении на вход терминала b автомат остается в том же состоянии B;
Bc → F - из состояния В при поступлении на вход терминала c автомат переходит в заключительное состояние F;
Bc → A - из состояния В при поступлении на вход терминала c автомат переходит в состояние А;
Aa → A - в состоянии А при поступлении на вход терминала а автомат остается в этом же состоянии А;
Ab → S - из состояния A при поступлении на вход терминала b автомат переходит в состояние S.
Полученный недетерминированный конечный автомат распознает цепочки языка, порождаемые праворекурсивной грамматикой G.
Теорема. Для произвольного конечного автомата существует эквивалентная праволинейная грамматика.
Доказательство. Каждому состоянию произвольного автомата поставлен в соответствие нетерминал грамматики, причем начальному состоянию будет соответствовать аксиома.
Тогда для каждой команды Ac → B в множество правил грамматики включим правило A → cB, причем в случае, если B - заключительное состояние, добавим правило A → c.
Эквивалентность исходного конечного автомата и построенной грамматики очевидна.
Теорема. Для каждой леворекурсивной грамматики существует эквивалентный конечный автомат.
Доказательство. Каждому нетерминальному символу произвольной леворекурсивной грамматики поставим в соответствие состояние конечного автомата, причем состояние, соответствующее аксиоме S, сделаем заключительным. Добавим еще одно состояние N и сделаем его начальным состоянием.
Каждому правилу грамматики A → Ba поставим в соответствие команду автомата Вa → A. Тогда каждому выводу в грамматике:
SÞA1akÞA2ak-1akÞ ... ÞAk-1a2a3...ak Þ a1a2 . . . ak однозначно соответствует следующая последовательность команд построенного автомата A:
Na1 → Ak-1; . . .; A2ak-1 → A1; A1ak → S.
Таким образом, язык L(G) = L(A).
Теорема. Для произвольного конечного автомата существует эквивалентная леворекурсивная грамматика.
Доказательство. Каждому состоянию произвольного автомата поставим в соответствие нетерминальный символ грамматики, добавим нетерминал S и сделаем его аксиомой.
Каждой команде Aa → B в множество правил включим соответствующее правило B → Aa, причем в том случае, если B - заключительное состояние, дополнительно введем правило S → Aa, а если A - начальное состояние, то дополнительно введем правило B → a.
Тогда последовательности команд:
A0a1 → A1; A1a2 → A2; . . . ; Ak-1ak → F
соответствует следующий вывод:
S Þ Ak-1ak Þ ... Þ A1a2a3...ak Þ a1a2a3...ak.
Важной особенностью автоматных грамматик является возможность представления их с помощью конечных графов. По графу грамматики легко отыскивается вывод нужной цепочки.
Любой вывод цепочки в автоматной грамматике соответствует пути в графе этой грамматики, который начинается из вершины S (вершины, помеченной аксиомой) и заканчивается в конечной вершине.
Пример. Построить конечный автомат, распознающий язык L(A) = {(ab)*}.
Сначала построим некоторую грамматику G, которая бы порождала язык L(A):
S → aA;
A → bS | b.
Проверим, действительно ли эта грамматика порождает язык L(A). Для этого построим несколько выводов возможных вариантов цепочек:
1) S Þ aA Þ ab;
2) S Þ aA Þ abS Þ abaA Þ abab;
3) S Þ aA Þ abS Þ abaA Þ ababS Þ ababaA Þ ababab; и т.д.
Таким образом, грамматика G действительно порождает язык L(A), следовательно, можно построить соответствующий этой грамматике конечный автомат. Для этого введем заключительное состояние F, начальное состояние соответствует аксиоме S.
b
 S А
S А
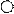
 a
a
b
F

Запишем преобразование правил вывода в команды:
Sa → A - из состояния S при поступлении на вход терминала а автомат переходит в состояние А;
Ab → S - из состояния А при поступлении на вход терминала a автомат переходит в состояние S;
Ab → F - из состояния А при поступлении на вход терминала b автомат переходит в заключительное состояние F.
Таким образом, построен недетерминированный конечный автомат, распознающий заданный язык L(G).
2.Автоматы с магазинной памятью
Автомат с магазинной памятью (МП-автомат) имеет рабочую ленту, которая организована в виде магазина.
МП-автомат - это семерка вида:
M = (К, Σ, Г, δ, p0, F, B0), где
К - конечное множество состояний;
Σ - алфавит;
Г - алфавит магазина;
δ - функция переходов;
p0 - начальное состояние;
F - множество заключительных состояний;
B0 - символ из множества Г для обозначения маркера дна магазина.
В общем случае данное определение соответствует недетерминированному автомату.
В отличие от конечного автомата для произвольного МП-автомата нельзя построить эквивалентный детерминированный автомат.
Основное использование распознавательных средств задания языков состоит в построении алгоритмов грамматического разбора. Поэтому необходимо для произвольной КС-грамматики уметь строить эквивалентный МП-автомат.
МП-автомат представляет интерес как средство разбора в КС-грамматиках произвольного вида. Этот факт сформулирован в следующей теореме.
Теорема. Языки, порождаемые КС-грамматиками, совпадают с языками, распознаваемыми МП-автоматами.
Доказательство. Существуют две стратегии разбора: восходящий и нисходящий разбор.
Рассмотрим обе стратегии разбора.
Восходящий разбор в МП-автомате
При восходящей стратегии необходимо найти основу и редуцировать ее к какому-нибудь нетерминалу в соответствии с правилами данной грамматики. Это можно сделать в том случае, если реализовать следующий алгоритм функционирования МП-автомата:
1) любой входной символ записывается в магазин;
2) если в верхушке магазина сформирована основа, совпадающая с правой частью правила, то она заменяется на нетерминал в левой части этого правила;
3) разбор заканчивается, если в магазине остается аксиома, а входная цепочка рассмотрена полностью.
В соответствии с этим алгоритмом для КС-грамматики G = (VT, VN, P, S) построим МП-автомат:
M = (К, VT, Г, δ, p0, F, B0), где Г = VT È VN È {B0},
K = {p0, F}, F = {f}.
Функция переходов δ будет содержать следующие команды:
а) p0, a, ε → p0, a - для любых a Î VT;
б) p0, ε, ϕ’ → p0, A - для всех правил A → ϕ Î P, где ϕ’ - зеркальное отображение ϕ;
в) p0, ε, SB0 → f, B0.
В общем случае команда выглядит так:
pi, σ, γ → pj, λ , где pi Î K – состояние автомата до выполнения команды, σÎVt – символ на входной ленте, γÎΓ - символ верхушки магазина, pj Î K – состояние автомата после выполнения команды, λÎΓ - символ, который записывается в магазин.
Таким образом, любому выводу в грамматике G взаимно однозначно соответствует последовательность команд построенного МП-автомата. Обратное построение КС-грамматики по произвольному МП-автомату также возможно, но не представляет практического интереса.
Рассмотрим пример восходящей стратегии разбора.
Пусть дана грамматика G:
S → S+A | S/A | A
A → a | (S);
VN={S, A}, VT={a, (, ), +, /}.
Для заданной КС-грамматики G необходимо построить МП-автомат.
Эквивалентный МП-автомат должен содержать следующие команды:
1. Команды переноса терминальных символов в магазин:
p0, a, ε → p0, a ;
p0, +, ε → p0, + ;
p0, /, ε → p0, / ;
p0, (, ε → p0, (;
p0, ), ε → p0, ).
Эти команды обеспечивают занесение терминального символа из входной ленты в магазин.
2. Команды редукции по правилам грамматики:
p0, ε, A+S → p0, S ;
p0, ε, A/S → p0, S ;
p0, ε, A → p0, S ;
p0, ε, )S( → p0, A ;
p0, ε, a → p0, A.
Эти команды заменяют зеркальное отображение правила, полученного в верхушке магазина, на нетерминал в левой части данного правила грамматики.
3. Команды проверки на завершение разбора:
p0, ε, SB0 → f, B0.
Разбор завершается, если в магазине остались аксиома и маркер дна магазина, а входная цепочка полностью рассмотрена.
Подадим на вход автомата цепочку a/(a+a) и выполним разбор. Процесс разбора представлен в таблице 1.
Нисходящий разбор в МП-автомате
На любом шаге нисходящего разбора должно применяться какое-либо правило. В начальный момент таким нетерминалом является аксиома. МП-автомат, выполняющий нисходящий разбор, работает по следующему алгоритму:
1) в начальный момент времени в магазин заносится аксиома: p0, ε, ε → p1, S;
2) для каждого правила A→ϕ∈P нетерминал в верхушке магазина заменяется на правую часть правила с помощью команды: p1, ε, A → p1, ϕ;
3) для каждого терминала aÎVT выполняется сравнение символа на входной ленте с символом в верхушке магазина и его поглощение: p1, a, a →p1, ε
4) разбор заканчивается по команде: p1,ε,B0 → f, B0.
Для грамматики, рассмотренной в предыдущем примере, разбор той же входной цепочки по нисходящей стратегии будет выполняться посредством следующего множества команд:
1) команда занесения аксиомы в магазин:
p0, ε, ε → p0, S;
2) команды замены нетерминала правой частью правила:
p1, ε, S → p1, S+A
p1, ε, S → p1, S/A
p1, ε, S → p1, A
p1, ε, A → p1, a
p1, ε, A → p1, (S);
3) команды сравнения и поглощения символа с входной ленты и символа в верхушке
магазина:
p1, a, a → p1, ε
p1, +, + → p1, ε
p1, /, / → p1, ε
p1, (, ( → p1, ε
p1, ), ) → p1, ε;
4) команда завершения разбора:
p1, ε, B0 → f, B0.
Процесс разбора цепочки представлен в таблице 2.
Рассмотренные выше МП-автоматы работают недетерминированно, то есть если цепочка принадлежит языку, порождаемому заданной грамматикой, то какой-то из вариантов функционирования автомата осуществит правильный разбор. Если же цепочка не принадлежит языку, то никакой из вариантов разбора не приведет к цели.
Отсутствие детерминированного эквивалентного автомата для произвольной КС-грамматики означает невозможность построения универсальной простой однопроходной программы синтаксического анализа. Поэтому для эффективного разбора необходимо выделять специальные классы КС-грамматик, удовлетворяющие требованиям конкретных типов анализаторов.
Если требуется выполнить разбор для произвольной КС-грамматики, то придется использовать детерминированную программную модель недетерминированного МП-автомата.
Понятие преобразователей
Автоматы с выходом называются преобразователями. В зависимости от вида функции, отображающей множество состояний и входных символов в множество выходных символов и новых состояний, а также от типа рабочей ленты различают разные виды преобразователей. Рассмотрим конечные автоматы-преобразователи.
Конечным преобразователем называется шестерка вида
P = (К, X, Y, f, g, q0), где
K - конечное множество состояний;
X - входной алфавит;
Y - выходной алфавит;
f - функция переходов;
g - функция выходов;
q0 - начальное состояние.
Типы отображений f и g определяют различные виды автоматов. Если g - отображение K ⋅ X в Y, то конечный преобразователь называется синхронным. В общем случае это отображение имеет вид K ⋅ X → Y*.
Пусть P = (К, X, Y, f, g, q0) - конечный преобразователь. Тогда отображение S(x) = g(q0, x), определенное для любой цепочки x Î X*, называется конечным преобразователем.
Заметим, что для того чтобы выходную цепочку y можно было считать переводом входной цепочки x, цепочка x должна перевести преобразователь из начального состояния в заключительное.
Тема 13. Автомат Мили
План лекции
1. Неинициальные Автоматы
2. Автомат Мили
Автоматы Мили и Мура являются неинициальными автоматами. В отображении S(x) = g(q0, x) зафиксируем начальное состояние q0, в котором автомат находится в начальный момент времени. Оно существенно влияет на процесс конечного преобразования, т.к. определяет не только результирующую цепочку, но и множество входных цепочек.
Рассмотрим поведение инициальных автоматов, которые могут начинать работать из любого указанного состояния. Такой автомат получает на вход одну цепочку бесконечной длины и перерабатывает её. Реакция такого преобразователя на определенные воздействия непредсказуема, если неизвестно его начальное состояние. Поэтому необходимо решить две задачи, имеющие важное практическое значение:
1) определение того состояния автомата, в котором он находится в момент, начиная с которого исследуется его поведение;
2) распознавание конечного состояния, в которое перешел автомат после завершения испытательной операции. Это состояние будет начальным для следующей серии испытаний.
Эти задачи анализа получили название экспериментов по распознаванию состояния.
Автомат Мили
Автомат Мили - это пятерка вида M = (К, X, Y, f, g), где:
K - множество состояний автомата;
X - входной алфавит;
Y - выходной алфавит;
f - функция переходов (отображение K ⋅ X → K);
g - функция выходов (отображение K ⋅ X → Y).
Как и любой другой автомат, автомат Мили можно представить в виде таблицы
или графа. В графе переходов автомата Мили на дугах указываются через символ ‘/’ входные и выходные символы. Таблица переходов состоит из двух частей: в левой части записываются значения функции выходов, в правой части - значения функции переходов.
Пример. Построим преобразователь, который распознает арифметические выражения, порождаемые грамматикой:
S → a+S | a−S | +S | −S | a
и устраняет из этих выражений избыточные унарные операции. Например, выражение –a+−а−+−а он переведет в –а−а+а. Во входном языке символ а представляет идентификатор и перед идентификатором допускается произвольная последовательность знаков унарных операции + и −. Заметим, что входной язык является регулярным множеством.
Пусть M = (К, X, Y, f, g), где
1. К = {q0, q1, q2, q3, q4},
2. X = {a,+, −},
3. Y = X.
Преобразователь М начинает работу в состоянии q0 и, чередуя состояния q0 и q4 на входном символе «−», определяет, четное или нечетное число знаков − предшествует первому символу а. Когда появляется а, преобразователь М переходит в состояние q1, допуская вход, и выдает а или −а в зависимости от того, четно или нечетно число появившихся минусов. Для следующих символов а он подсчитывает, четно или нечетно число предшествующих минусов, с помощью состояний q2 и q3. Единственное различие между парами q2, q3 и q0, q4 состоит в том, что если символу а предшествует четное число минусов, то первая из них выдает +а, а не только а.
Таблица переходов выглядит следующим образом:
| <== предыдущая страница | | | следующая страница ==> |
| Тема 10. Преобразования КС-грамматик | | | Тема 14. Автомат Мура |
Дата добавления: 2015-07-26; просмотров: 150; Нарушение авторских прав

Мы поможем в написании ваших работ!