Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Интеллектуальный анализ данных Data-mining
Содержание понятия знания. Классификация видов знаний
Для обоснования принятия решений необходимы знания. Их добывают из различных источников.
Понятие «знания» рассматривается с различных точек зрения. В соответствии с этим имеется много определений этого понятия. Энциклопедический словарь определяет знания как «проверенный практикой результат познания действительности, верное ее отражение в мышлении человека». Применительно к ситуации с использованием компьютерных информационных систем (ИС) и, в частности ИАС, можно добавить «и в компьютерной ИС». По определению Гавриловой Т.А. и Хорошевского В.Ф. знания это «закономерности предметной области (принципы, связи, законы), полученные в результате практической деятельности и профессионального опыта, позволяющие специалистам ставить и решать задачи в этой области».
На начальном этапе подготовки данных к использованию в аналитической сфере они же представляют знания как «хорошо структурированные данные или метаданные». Знания различаются по многим признакам. Соответственно в литературе приводится классификация различных видов знаний.
1. Различают фактические и стратегические знания.
Фактические — это такие знания, которые позволяют специалисту предметной области решать конкретные задачи из бизнес-сферы или в каком-либо другом виде деятельности. К ним относятся факты, взаимосвязи, системы понятий, правила. Стратегические — позволяют определить поведение объектов в ближайшем или отдаленном будущем.
2. Факты и эвристики.
Факты — это хорошо известные и описанные обстоятельства. К ним относятся также экономические категории, известные и описанные закономерности и так далее.
Эвристики — знания, опыт, навыки специалистов в соответствующих предметных областях.
Они являются объектом изучения и внедрения в информационные системы различного назначения.
3. Декларативные и процедурные знания.
Первые являются очевидными, например: выручка — сумма, полученная в результате продажи товаров. Товар — изделие, предназначенное для продажи.
Процедурные — по существу алгоритмы преобразования декларативных знаний, действий над ними.
4. Интенсиональные и экстенсиональные знания.
Первые являются знаниями о связях между объектами (их атрибутами) рассматриваемой предметной области. Вторые — свойства объектов, их состояния, значения свойств в пространстве и динамике.
5. Глубинные и поверхностные знания.
Глубинные знания содержат подробные сведения о структуре предметной области, законах поведения структуры в целом и отдельных ее элементов, достоверные и полные отражения взаимосвязей элементов структуры и т.д. Например: подробные сведения об устройстве компьютера или мобильного телефона, позволяющие производить проектирование их или ремонт.
Поверхностные знания касаются лишь внешних свойств и связей с рассматриваемым объектом(ами). Перечень необходимых сведений о пользовательских свойствах упомянутых или других изделий.
6. Жесткие и мягкие знания.
Жесткие знания отражают системы или объекты с четко выраженными свойствами, связями, поведением, которые легко описываются качественными и количественными признаками, например описываются логико-дедуктивной системой показателей.
Мягкие знания отображают соответственно системы и объекты с трудно поддающимися описанию или формализации свойствами и связями. Дают нечеткие, размытые решения и множественность рекомендаций.
Взаимосвязь между видами знаний отражена на рисунке 4.1.
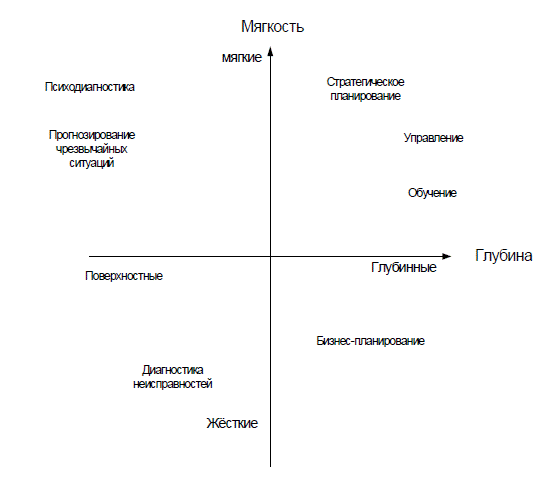
Рис. 4.1. Характеристики знаний
Задачи Data mining
Следует различать два различных процесса получения знаний. Первый — это «извлечение» их из живого источника — эксперта, специалиста с целью их идентификации и возможной формализации, помещения в базу знаний и построения на этой основе экспертных систем, а также в других целях. Такой процесс относят к инженерии знаний. Другой — это «добыча» скрытых от пользователя знаний из данных, помещенных в различного рода компьютерные информационные системы, в том числе базы данных различного назначения, информационные хранилища. Процесс второго рода называют Data mining — используют русский перевод «интеллектуальный анализ». Предметом нашего изучения является Data mining.
В связи с совершенствованием технологий записи и хранения данных на людей обрушились колоссальные потоки информационной руды в самых различных областях. Деятельность любого предприятия (коммерческого, производственного, медицинского, научного и т.д.) теперь сопровождается регистрацией и записью всех подробностей его деятельности. Соответственно накапливается много различной информации, которую возможно каким-то образом переработать и использовать .
Специфика современных требований к такой переработке следующая:
· Данные имеют неограниченный объем;
· Данные являются разнородными (количественными, качественными, текстовыми);
· Результаты должны быть конкретны и понятны;
· Инструменты для обработки «сырых» данных должны быть просты в использовании.
В основу современной технологии Data Mining (discovery-driven data mining) положена концепция шаблонов (паттернов), отражающих фрагменты многоаспектных взаимоотношений в данных. Эти шаблоны представляют собой закономерности, свойственные подвыборкам данных, которые могут быть компактно выражены в понятной человеку форме. Поиск шаблонов производится методами, не ограниченными рамками априорных предположений о структуре выборки и виде распределений значений анализируемых показателей.
Примерами заданий на такой поиск при использовании Data Mining могут служить следующие вопросы:
1. Встречаются ли точные шаблоны в описаниях людей, подверженных повышенному травматизму?
2. Имеются ли характерные портреты клиентов, которые, по всей вероятности, собираются отказаться от услуг телефонной компании?
3. Существуют ли стереотипные схемы покупок для случаев мошенничества с кредитными карточками?
Важное положение Data Mining — нетривиальность разыскиваемых шаблонов. Это означает, что найденные шаблоны должны отражать неочевидные, неожиданные регулярности в данных, составляющие так называемые скрытые знания (hidden knowledge). К обществу пришло понимание, что сырые данные содержат глубинный пласт знаний, при грамотной раскопке которого могут быть обнаружены настоящие самородки. На рисунке 1 показаны уровни знаний и инструменты для их извлечения.
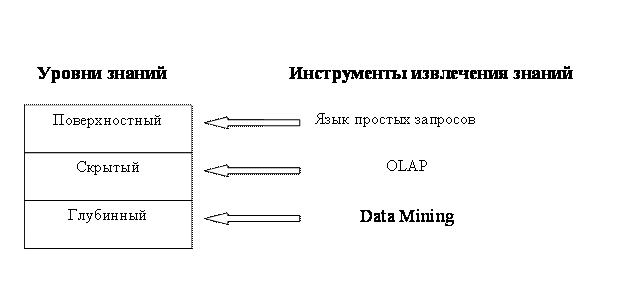
Рисунок 1. Уровни знаний, извлекаемых из данных.
Data Mining — это процесс обнаружения в «сырых» данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Для обработки накопленных в различных источниках и местах сбора и хранения данных и выполнения интеллектуального анализа используются все достижения математической науки и информационных технологий. В первую очередь используются методы линейной алгебры, классического математического анализа, дискретной математики, многомерного статистического анализа.
В экономической предметной области применение методов поиска решений, условий неотрицательности и других свойств математических моделей путем дедуктивного получения следствий, исходя из предварительно сформулированных предпосылок, относится к разделу экономической науки, называемому математическая экономика.
Анализ количественных закономерностей и взаимозависимостей в экономике, который выполняется статистическими методами, относится к эконометрике.
Традиционная математическая статистика долгое время являлась основной методологией анализа данных в экономической и других предметных областях. Однако базовая концепция усреднения по выборке часто приводит к операциям над фиктивными величинами. В экономике средние значения ряда показателей по различным предприятиям иногда создают искаженное представление об отсталости или наоборот о незаурядных успехах ряда предприятий, отраслей или регионов — сглаживают их.
По этой причине появился ряд методик, которые относят к специфическим для Data mining-a. Эти методики позволяют избежать таких ситуаций. В таблице приведены примеры постановок задач для OLAP-методик, основанных на математической статистике, и специфических методов Data Mining.

Выше показано, что работа по интеллектуальной обработке данных происходит в сфере закономерностей.
Основными задачами интеллектуального анализа являются:
− выявление взаимозависимостей, причинно-следственных связей, ассоциаций и аналогий,
− определение значений факторов времени, локализация событий или явлений по месту;
− классификация событий и ситуаций, определение профилей различных факторов;
− прогнозирование хода процессов, событий.
Главной задачей здесь является определение закономерностей в исследуемых процессах, взаимосвязей и взаимовлияния различных факторов, поиск крупных «непривычных» отклонений, прогноз хода различных процессов в области мягких и глубинных знаний.
Одновременно с этим многомерный статистический анализ твердо удерживает свои позиции в жесткой области знаний. Он делится на: факторный, дисперсионный, регрессионный, корреляционный, кластерный анализ (является также сферой интересов data mining-a). Эти методы позволяют решать многочисленные задачи в области экономики, менеджмента, юриспруденции, которые являются составной частью аналитической подготовки принятия решений.
Стадии ИАД
В общем случае процесс интеллектуального анализа данных (ИАД) состоит из трёх стадий (рис. 2):
1) выявление закономерностей (свободный поиск);
2) использование выявленных закономерностей для предсказания неизвестных значений (прогностическое моделирование);
3) анализ исключений, предназначенный для выявления и толкования аномалий в найденных закономерностях.

Рисунок 2. Стадии процесса интеллектуального анализа данных
1. Свободный поиск (Discovery)
Свободный поиск определяется как процесс исследования исходной БД на предмет поиска скрытых закономерностей без предварительного определения гипотез относительно вида этих закономерностей. Другими словами, сама программа берет на себя инициативу в деле поиска интересных аномалий, или шаблонов, в данных, освобождая аналитика от необходимости обдумывания и задания соответствующих запросов. Этот подход особенно ценен при исследовании больших баз данных, имеющих значительное количество скрытых закономерностей, большинство из которых было бы упущено при непосредственном поиске путем прямых запросов пользователя к исходным данным.
В качестве примера свободного поиска по инициативе системы рассмотрим исследование реестра физических лиц. Если инициатива принадлежит пользователю, он может построить запрос типа "Каков средний возраст директоров предприятий отрасли промышленности строительных материалов, расположенных в Иванове и находящихся в собственности субъекта Федерации?" и получить ответ - 48. В системе, обеспечивающей стадию свободного поиска, пользователь может поступить иначе и запросить у системы найти что-нибудь интересное относительно того, что влияет на атрибут Возраст. Система начнет действовать так же, как и аналитик-человек, т. е. искать аномалии в распределении значений атрибутов, в результате чего будет произведен список логических правил типа "ЕСЛИ ..., ТО ...", в том числе, например:
· ЕСЛИ Профессия="Программист", ТО Возраст<=30 в 61% случаев;
· ЕСЛИ Профессия="Программист", ТО Возраст<=60 в 98% случаев.
Аналогично, при исследовании реестра юридических лиц аналитика может заинтересовать атрибут «Форма_собственности». В результате свободного поиска могут быть получены правила:
· ЕСЛИ Основной_вид_деятельности="Общеобразовательные детские школы", ТО Форма_собственности="Муниципальная собственность" в 84% случаев;
· ЕСЛИ Вид_деятельности="Наука и научное обслуживание", ТО Форма_собственности="Частная собственность" в 73% случаев.
Стадия свободного поиска может выполняться посредством:
· индукции правил условной логики (как в приведенных примерах) - с их помощью, в частности, могут быть компактно описаны группы похожих обучающих примеров в задачах классификации и кластеризации;
· индукции правил ассоциативной логики - то есть того, что было определено в рамках классификации задач ИАД по типам извлекаемой информации как выявление ассоциаций и последовательностей;
· определения трендов и колебаний в динамических процессах, то есть исходного этапа задачи прогнозирования.
Стадия свободного поиска, как правило, должна включать в себя не только генерацию закономерностей, но и проверку их достоверности на множестве данных, не принимавшихся в расчет при их формулировании.
2. Прогностическое моделирование (Predictive Modeling)
На второй стадии ИАД, используются «плоды» работы первой, то есть найденные в БД закономерности применяются для предсказания неизвестных значений:
· при классификации нового объекта можно с известной уверенностью отнести его к определенной группе результатов рассмотрения известных значений его атрибутов;
· при прогнозировании динамического процесса результаты определения тренда и периодических колебаний могут быть использованы для вынесения предположений о вероятном развитии некоторого динамического процесса в будущем.
Возвращаясь к рассмотренным примерам, продолжим их на данную стадию. Зная, что некто Иванов - программист, можно быть на 61% уверенным, что его возраст <=30 годам, и на 98% - что он <=60 годам. Аналогично, можно сделать заключение о 84% вероятности того, что некоторое новое юридическое лицо будет находиться в муниципальной собственности, если его основной вид деятельности - "Общеобразовательные детские школы".
Следует отметить, что свободный поиск раскрывает общие закономерности, т. е. индуктивен, тогда как любой прогноз выполняет догадки о значениях конкретных неизвестных величин, следовательно, дедуктивен. Кроме того, результирующие конструкции могут быть как прозрачными, т. е. допускающими разумное толкование (как в примере с произведенными логическими правилами), так и нетрактуемыми - "черными ящиками".
3. Анализ исключений (Forensic Analysis)
Предметом данного анализа являются аномалии в раскрытых закономерностях, то есть необъясненные исключения. Чтобы найти их, следует сначала определить норму (стадия свободного поиска), вслед за чем выделить ее нарушения. Так, определив, что 84% общеобразовательных школ отнесены к муниципальной форме собственности, можно задаться вопросом - что же входит в 16%, составляющих исключение из этого правила? Возможно, им найдется логическое объяснение, которое также может быть оформлено в виде закономерности. Но может также статься, что мы имеем дело с ошибками в исходных данных, и тогда анализ исключений может использоваться в качестве инструмента очистки сведений в хранилище данных.
Методы ИАД
Все методы ИАД подразделяются на две большие группы по принципу работы с исходными обучающими данными.
В первом случае исходные данные могут храниться в явном детализированном виде и непосредственно использоваться для прогностического моделирования и/или анализа исключений; это так называемые методы рассуждений на основе анализа прецедентов. Главной проблемой этой группы методов является затрудненность их использования на больших объемах данных, хотя именно при анализе больших хранилищ данных методы ИАД приносят наибольшую пользу.
Во втором случае информация вначале извлекается из первичных данных и преобразуется в некоторые формальные конструкции (их вид зависит от конкретного метода). Согласно предыдущей классификации, этот этап выполняется на стадии свободного поиска, которая у методов первой группы в принципе отсутствует. Таким образом, для прогностического моделирования и анализа исключений используются результаты этой стадии, которые гораздо более компактны, чем сами массивы исходных данных. При этом полученные конструкции могут быть либо "прозрачными" (интерпретируемыми), либо "черными ящиками" (нетрактуемыми).
Две эти группы и примеры входящих в них методов представлены на рисунке 3.
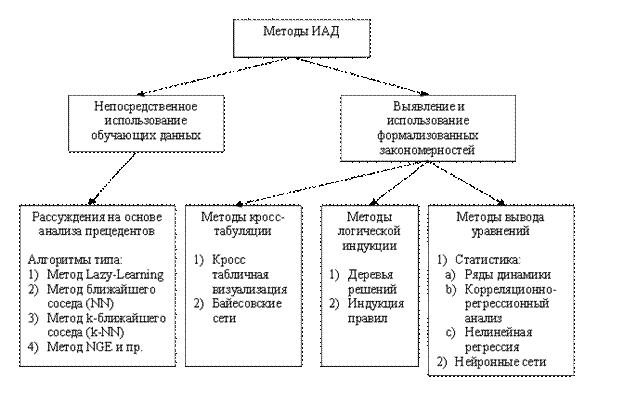
Рис. 3 Классификация технологических методов ИАД
1. Непосредственное использование обучающих данных
Обобщенный алгоритм Lazy-Learning, относящийся к рассматриваемой группе, выглядит так: на вход классификатора подается пример, на выходе ожидается предсказание включающего его класса. Каждый пример представляется точкой в многомерном пространстве свойств (атрибутов), принадлежащей некоторому классу. Каждый атрибут принимает непрерывные значения либо дискретные значения из фиксированного набора. Для примера возвращается его наиболее вероятный класс.
Особенность этой группы методов состоит в том, что предсказание неизвестных значений выполняется на основе явного сравнения нового объекта (примера) с известными примерами. В случае большого количества обучающих примеров, чтобы не сканировать последовательно все обучающее множество для классификации каждого нового примера, иногда используется прием выборки относительно небольшого подмножества "типичных представителей" обучающих примеров, на основе сравнения с которыми и выполняется классификация. Однако, этим приемом следует пользоваться с известной осторожностью, так как в выделенном подмножестве могут не быть отражены некоторые существенные закономерности.
Что касается самого известного представителя этой группы - метода k-ближайшего соседа, - он более приспособлен к тем предметным областям, где атрибуты объектов имеют преимущественно численный формат, так как определение расстояния между примерами в этом случае является более естественным, чем для дискретных атрибутов.
2. Выявление и использование формализованных закономерностей
Методы этой группы извлекают общие зависимости из множества данных и позволяют затем применять их на практике. Они отличаются друг от друга:
· по типам извлекаемой информации (которые определяются решаемой задачей);
· по способу представления найденных закономерностей.
Формализм, выбранный для выражения закономерностей, позволяет выделить три различных подхода, каждый из которых уходит своими корнями в соответствующие разделы математики:
· методы кросс-табуляции;
· методы логической индукции;
· методы вывода уравнений.
Логические методы наиболее универсальны в том смысле, что могут работать как с численными, так и с другими типами атрибутов. Построение уравнений требует приведения всех атрибутов к численному виду, тогда как кросс-табуляция, напротив, требует преобразования каждого численного атрибута в дискретное множество интервалов.
Методы кросс-табуляции
Кросс-табуляция является простой формой анализа, широко используемой в генерации отчетов средствами систем оперативной аналитической обработки (OLAP). Двумерная кросс-таблица представляет собой матрицу значений, каждая ячейка которой лежит на пересечении значений атрибутов. Расширение идеи кросс-табличного представления на случай гиперкубической информационной модели является, как уже говорилось, основой многомерного анализа данных, поэтому эта группа методов может рассматриваться как симбиоз многомерного оперативного анализа и интеллектуального анализа данных.
Кросс-табличная визуализация является наиболее простым воплощением идеи поиска информации в данных методом кросс-табуляции. Строго говоря, этот метод не совсем подходит под отмеченное свойство ИАД - переход инициативы к системе в стадии свободного поиска. На самом деле кросс-табличная визуализация является частью функциональности OLAP. Здесь система только предоставляет матрицу показателей, в которой аналитик может увидеть закономерность. Но само предоставление такой кросс-таблицы имеет целью поиск "шаблонов информации" в данных для поддержки принятия решений, то есть удовлетворяет приведенному определению ИАД. Поэтому неслучайно, что множество авторов все же относит кросс-табличную визуализацию к методам ИАД.
К методам ИАД группы кросс-табуляции относится также использование байесовских сетей (Bayesian Networks), в основе которых лежит теорема Байеса теории вероятностей для определения апостериорных вероятностей составляющих полную группу попарно несовместных событий по их априорным вероятностям. Байесовские сети активно использовались для формализации знаний экспертов в экспертных системах, но с недавних пор стали применяться в ИАД для извлечения знаний из данных.
Можно отметить четыре достоинства байесовских сетей как средства ИАД:
· поскольку в модели определяются зависимости между всеми переменными, легко обрабатываются ситуации, когда значения некоторых переменных неизвестны;
· построенные байесовские сети просто интерпретируются и позволяют на этапе прогностического моделирования легко производить анализ по сценарию "что - если";
· подход позволяет естественным образом совмещать закономерности, выведенные из данных, и фоновые знания, полученные в явном виде (например, от экспертов);
· использование байесовских сетей позволяет избежать проблемы переподгонки (overfitting), то есть избыточного усложнения модели, чем страдают многие методы (например, деревья решений и индукция правил) при слишком буквальном следовании распределению зашумленных данных.
Байесовские сети предлагают простой наглядный подход ИАД и широко используются на практике.
Методы логической индукции
Методы данной группы являются, пожалуй, наиболее выразительными, в большинстве случаев оформляя найденные закономерности в максимально "прозрачном" виде. Кроме того, производимые правила, в общем случае, могут включать как непрерывные, так и дискретные атрибуты. Результатами применения логической индукции могут быть построенные деревья решений или произведенные наборы символьных правил.
Деревья решений
Деревья решений являются упрощенной формой индукции логических правил. Основная идея их использования заключается в последовательном разделении обучающего множества на основе значений выбранного атрибута, в результате чего строится дерево, содержащее:
· терминальные узлы (узлы ответа), задающие имена классов;
· нетерминальные узлы (узлы решения), включающие тест для определенного атрибута с ответвлением к поддереву решений для каждого значения этого атрибута.
В таком виде дерево решений определяет классификационную процедуру естественным образом: любой объект связывается с единственным терминальным узлом. Эта связь начинается с корня, проходит путь по дугам, которым соответствуют значения атрибутов, и доходит до узла ответа с именем класса.
Индукция правил
Популярность деревьев решений проистекает из быстроты их построения и легкости использования при классификации. Более того, деревья решений могут быть легко преобразованы в наборы символьных правил - генерацией одного правила из каждого пути от корня к терминальной вершине. Однако, правила в таком наборе будут неперекрывающимися, потому что в дереве решений каждый пример может быть отнесен к одному и только к одному терминальному узлу. Более общим (и более реальным) является случай существования теории, состоящей из набора неиерархических перекрывающихся символьных правил. Значительная часть алгоритмов, выполняющих индукцию таких наборов правил, объединяются стратегией отделения и захвата (separate-and-conquer), или покрывания (covering). Эта стратегия индукции характеризуется следующим образом:
· произвести правило, покрывающее часть обучающего множества;
· удалить покрытые правилом примеры из обучающего множества (отделение);
· последовательно обучиться другим правилам, покрывающим группы оставшихся примеров (захват), пока все примеры не будут объяснены.
Сравнение возможностей деревьев решений и индукции правил
Индукция правил и деревья решений, будучи способами решения одной задачи, значительно отличаются по своим возможностям. Несмотря на широкую распространенность деревьев решений, индукция правил по ряду причин представляется более предпочтительным подходом.
1. Деревья решений часто довольно сложны и тяжелы для понимания.
2. Непременное требование неперекрываемости правил в алгоритмах обучения деревьев решений навязывает жесткое ограничение на возможность выражения существующих закономерностей. Одна из проблем, вытекающих из этого ограничения - проблема дублированного поддерева. Часто случается, что идентичные поддеревья оказываются в процессе обучения в разных местах дерева решений вследствие фрагментации пространства исходных примеров, обязательной по ограничению на неперекрываемость правил. Индукция отделения и захвата не ставит такого ограничения и, следовательно, менее чувствительна к этой проблеме.
3. Построение деревьев решений затруднено при большом количестве исходной информации (что чаще всего имеет место при интеллектуальном анализе хранилищ данных). Для решения этой проблемы часто выделяют относительно небольшое подмножество имеющихся обучающих примеров и на его основе сооружают дерево решений. Такой подход во многих случаях приводит к потере информации, скрытой в проигнорированных при индукции примерах.
С другой стороны, индукция правил осуществляется значительно более сложными (и медленными) алгоритмами, чем индукция деревьев решений. Особенно большие трудности возникают с поступрощением построенной теории, в отличие от простоты подрезания деревьев решений: отсечение ветвей в дереве решений никогда не затронет соседние ветви, тогда как отсечение условий правила оказывает влияние на все перекрывающиеся с ним правила.
С другой стороны, отсечение условий от правила означает его обобщение, то есть в новом виде оно будет покрывать больше положительных и больше отрицательных примеров. Следовательно, эти дополнительные положительные и отрицательные примеры должны быть исключены из обучающего множества, дабы не воздействовать на индукцию последующих правил
Следовательно, исходя из проведенного сравнения, можно заключить, что построение деревьев решений оправдано в несложных задачах при небольшом количестве исходной информации благодаря простоте и быстроте их индукции. Однако при анализе больших объемов данных, накопленных в хранилищах, использование методов индукции правил предпочтительнее, несмотря на их относительную сложность.
Методы вывода уравнений
Методы вывода уравнений пытаются выразить закономерности, скрытые в данных, в форме математических выражений. Поэтому они способны работать только с атрибутами численного типа, тогда как другие атрибуты должны быть искусственно закодированы численными значениями. Отсюда вытекает несколько проблем, ограничивающих использование этих методов на практике. Тем не менее, они широко применяются во многих приложениях.
Статистика
Классические методы статистического анализа применяются в средствах ИАД чаще всего для решения задачи прогнозирования.
1. Выявление тенденций динамических рядов. Тенденцию среднего уровня можно представить в виде графика или аналитической функции, вокруг значения которой варьируют фактические значения уровней исследуемого процесса. Часто тенденции среднего уровня называют детерминированной компонентой процесса. Детерминированная компонента обычно представляется достаточно простой аналитической функцией - линейной, параболической, гиперболической, экспоненциальной, - параметры которой подбираются согласно историческим данным для лучшей аппроксимации исторических данных.
2. Гармонический анализ. Во многих случаях сглаживание рядов динамики с помощью определения тренда не дает удовлетворительных результатов, так как в остатках наблюдается автокоppеляция. Причиной автокоppелиpованности остатков могут быть нередко встречающиеся в pядах динамики заметные периодические колебания относительно выделенной тенденции. В таких случаях следует прибегать к гармоническому анализу, то есть к выделению из динамического ряда периодической составляющей. По результатам выделения из динамического ряда тренда и периодической составляющей может выполняться статистический прогноз процесса по принципу экстраполяции, по предположению, что параметры тренда и колебаний сохранятся для прогнозируемого периода.
3. Корреляционно-регрессионный анализ. В отличие от функциональной (жестко детерминированной) связи, статистическая (стохастически детерминированная) связь между переменными имеет место тогда, когда с изменением значения одной из них вторая может в определенных пределах принимать любые значения с некоторыми вероятностями, но ее среднее значение или иные статистические характеристики изменяются по определенному закону. Частным случаем статистической связи, когда различным значениям одной переменной соответствуют различные средние значения другой, является корреляционная связь. Метод корреляционно-регрессионного анализа хорошо изучен и широко применяется на практике. Получаемые в результате применения анализа корреляционно-регрессионные модели (КРМ) обычно достаточно хорошо интерпретируемы и могут использоваться в прогностическом моделировании. Но невозможно применять этот вид анализа, не имея глубоких знаний в области статистики. Теоретическая подготовка аналитика играет здесь особенно важную роль, поэтому немногие существующие средства ИАД предлагают метод корреляционно-регрессионного анализа в качестве одного из инструментов обработки данных.
4. Корреляция рядов динамики. Проблема изучения причинных связей во времени очень сложна, и полное решение всех задач такого изучения до сих пор не разработано. Основная сложность состоит в том, что при наличии тренда за достаточно длительный промежуток времени большая часть суммы квадратов отклонений связана с трендом; при этом, если два признака имеют тренды с одинаковым направлением изменения уровней, то это вовсе не будет означать причинной зависимости. Следовательно, чтобы получить реальные показатели корреляции, необходимо абстрагироваться от искажающего влияния трендов - вычислить отклонения от трендов и измерить корреляцию колебаний. Однако, не всегда допустимо переносить выводы о тесноте связи между колебаниями на связь рядов динамики в целом.
Нейронные сети
Искусственные нейронные сети как средство обработки информации моделировались по аналогии с известными принципами функционирования биологических нейронных сетей. Их структура базируется на следующих допущениях:
· обработка информации осуществляется во множестве простых элементов - нейронов;
· сигналы между нейронами передаются по связям от выходов ко входам;
· каждая связь характеризуется весом, на который умножается передаваемый по ней сигнал;
· каждый нейрон имеет активационную функцию (как правило, нелинейную), аргумент которой рассчитывается как сумма взвешенных входных сигналов, а результат считается выходным сигналом.
Таким образом, нейронные сети представляют собой наборы соединенных узлов, каждый из которых имеет вход, выход и активационную функцию (как правило, нелинейную). Они обладают способностью обучаться на известном наборе примеров обучающего множества. Обученная нейронная сеть представляет собой "черный ящик" (нетрактуемую или очень сложно трактуемую прогностическую модель), которая может быть применена в задачах классификации, кластеризации и прогнозирования.
Обучение нейронной сети заключается в подстройке весовых коэффициентов, связывающих выходы одних нейронов со входами других. Обучение сети может производиться по одному из двух базовых сценариев:
· обучение с учителем (supervised training) - наиболее типичный случай, когда для каждого вектора значений входных переменных примера обучающего множества известен желаемый вектор значений выходных переменных; такой способ обучения применяется в задачах классификации и прогнозирования;
· обучение без учителя (unsupervised learning) - механизм настройки весов сети в случае, когда известны только значения входных переменных примеров обучающего множества; обученные таким способом нейронные сети выполняют задачу кластеризации.
Имеется ряд недостатков, ограничивающих использование нейронных сетей в качестве инструмента ИАД.
1. Обученные нейронные сети являются нетрактуемыми моделями - "черными ящиками", поэтому логическая интерпретация описанных ими закономерностей практически невозможна (за исключением простейших случаев).
2. Будучи методом группы вывода уравнений, нейронные сети могут обрабатывать только численные переменные. Следовательно, переменные других типов, как входные, так и выходные, должны быть закодированы числами. При этом недостаточно заменить переменную, принимающую значения из некоторой области определения, одной численной переменной, так как в этом случае могут быть получены некорректные результаты. Таким образом, при большом количестве нечисловых переменных с большим количеством возможных значений использование нейронных сетей становится совершенно невозможным.
Главной проблемой обучения нейронных сетей является синтез структуры сети, способной обучиться на заданном обучающем множестве. Нет никакой гарантии, что процесс обучения сети определенной структуры не остановится, не достигнув допустимого порога ошибки, или не попадет в локальный минимум. Хотя многослойные сети широко применяются для классификации и аппроксимации функций, их структурные параметры до сих пор должны определяться путем проб и ошибок.
Таким образом, нейронные сети - довольно мощный и гибкий инструмент ИАД - должны применяться с известной осторожностью и подходят не для всех проблем, требующих интеллектуального анализа корпоративных данных.
Типы закономерностей
Выделяют пять стандартных типов закономерностей, которые позволяют выявлять методы Data Mining: ассоциация, последовательность, классификация, кластеризация и прогнозирование.
Ассоциация имеет место в том случае, если несколько событий связаны друг с другом. Например, исследование, проведенное в супермаркете, может показать, что 65% купивших кукурузные чипсы берут также и "кока-колу", а при наличии скидки за такой комплект "колу" приобретают в 85% случаев. Располагая сведениями о подобной ассоциации, менеджерам легко оценить, насколько действенна предоставляемая скидка.
Если существует цепочка связанных во времени событий, то говорят о последовательности. Так, например, после покупки дома в 45% случаев в течение месяца приобретается и новая кухонная плита, а в пределах двух недель 60% новоселов обзаводятся холодильником.
С помощью классификации выявляются признаки, характеризующие группу, к которой принадлежит тот или иной объект. Это делается посредством анализа уже классифицированных объектов и формулирования некоторого набора правил.
Кластеризация отличается от классификации тем, что сами группы заранее не заданы. С помощью кластеризации средства Data Mining самостоятельно выделяют различные однородные группы данных.
Основой для всевозможных систем прогнозирования служит историческая информация, хранящаяся в БД в виде временных рядов. Если удается построить, найти шаблоны, адекватно отражающие динамику поведения целевых показателей, есть вероятность, что с их помощью можно предсказать и поведение системы в будущем.
Особенно широко методы ИАД применяются в бизнес-приложениях аналитиками и руководителями компаний. Для этих категорий пользователей разрабатываются инструментальные средства высокого уровня, позволяющие решать достаточно сложные практические задачи без специальной математической подготовки. Актуальность использования ИАД в бизнесе связана с жесткой конкуренцией, возникшей вследствие перехода от «рынка производителя» к «рынку потребителя». В этих условиях особенно важно качество и обоснованность принимаемых решений, что требует строгого количественного анализа имеющихся данных. При работе с большими объемами накапливаемой информации необходимо постоянно оперативно отслеживать динамику рынка, а это практически невозможно без автоматизации аналитической деятельности.
Типовые задачи для методов ИАД
Прогнозирование – одна из самых распространенных задач ИАД. В частности, при планировании и составлении бюджета необходимо прогнозировать объемы продаж и другие параметры с учетом многочисленных взаимосвязанных факторов – сезонных, региональных, общеэкономических и т.д. Можно также выявлять корреляции в продажах, например «покупке компьютера, как правило, сопутствует покупка блока бесперебойного питания».
Маркетинговый анализ. Чтобы разработать эффективный маркетинговый план, нужно знать, каким образом на уровень продаж влияют такие факторы как стоимость товара, затраты на продвижение продукции и рекламу. Нейросетевые модели позволяют менеджерам и аналитикам прогнозировать подобное влияние.
Анализ работы персонала. Производительность труда служащих зависит от уровня подготовки, от оплаты труда, опыта работы, взаимоотношений с руководством и т.д. Проанализировав влияние этих факторов, можно выработать методику повышения производительности труда, а также предложить оптимальную стратегию подбора кадров в будущем.
Анализ эффективности продажи товаров по почте. Если компания занимается рассылкой рекламы и образцов продукции по почте, то имеет смысл оценить эффективность подобной деятельности. При этом можно выявить круг потенциальных покупателей, и оценить вероятность совершения ими покупки. Кроме того, можно опробовать различные формы переписки и выбрать наиболее удачные.
Профилирование клиентов. С помощью нейросетевых моделей можно среди многочисленных клиентов фирмы выбрать тех, сотрудничество с которыми наиболее выгодно – получить портрет «типичного клиента компании». Кроме того, можно выяснить, почему работа с некоторыми из заказчиков стала неэффективной, и выработать стратегию поиска подходящих клиентов в будущем. Эта задача чаще всего решается менеджерами по продажам, а для банков, например, особый интерес представляет возможность оценки кредитоспособности клиентов.
Оценка потенциальных клиентов. Планируя предварительные переговоры имеет смысл определить, с какой долей вероятности они закончатся заключением договора (или продажей продукции). Анализ опыта работы с клиентами позволяет выявить характерные особенности тех заявок, которые закончились реальными продажами. Используя результаты данного анализа, менеджеры могут остановиться на более перспективных заявках клиентов.
Анализ результатов маркетинговых исследований. Чтобы оценить реакцию покупателей на политику компании в области распространения продукции, ценообразования, а также на характеристики самой продукции, необходимо, наряду с анализом продаж, проводить опросы покупателей. Это позволяет усовершенствовать процесс принятия решений по ценам и характеристикам выпускаемой продукции (дизайн, функциональность, упаковка).
Анализ работы региональных отделений компании. С помощью нейросетевых моделей можно сравнивать результаты деятельности региональных отделений или филиалов компании и определять, от чего зависит эффективность их работы (географическое положение, численность персонала, ассортимент продукции/услуг и т.д.). Результаты используются для оптимизации работы «отстающих» отделений, а также при планировании создания новых филиалов.
Сравнительный анализ конкурирующих фирм. Почему некоторые компании процветают и удерживают прочные позиции на рынке, а другие нет? Какие сферы бизнеса самые выгодные? Чтобы ответить на эти вопросы можно сравнить деятельность конкурирующих компаний и выяснить, какие факторы определяют прибыльность их бизнеса.
Очевидно, что перечисленные виды задач актуальны практически для всех отраслей бизнеса: банковского дела и страхования (выявление злоупотреблений с кредитными карточками, оценка кредитных рисков, оценка закладных, выявление профилей пользователей, оценка эффективности региональных отделений, вероятность подачи заявки на выплату страховки и др.), финансовых рынков (прогнозирование, анализ портфелей, моделирование индексов), производства (прогнозирование спроса, контроль качества, оценка дизайна продукции), торговли и т. д.
| <== предыдущая страница | | | следующая страница ==> |
| Требования, предъявляемые к OLAP-системам | | | Тема 5 Основы создания и применения информационно-аналитических систем |
Дата добавления: 2014-02-26; просмотров: 1664; Нарушение авторских прав

Мы поможем в написании ваших работ!