Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Глава 2. методы анализа двух переменных
2.1. Меры связи двух переменных
В теории анализа данных предложено большое число различных мер связи двух признаков. Это объясняется тем, что исследователи в области экономических наук, в отличие от их коллег, работающих в области “точных” наук, сталкиваются с разнообразными шкалами измерения переменных и их сочетанием. Так, в справочнике И.Г. Венецкого и В.И. Венецкой указаны следующие коэффициенты, с помощью которых может измеряться теснота корреляционной связи между двумя признаками (факторным и результативным по терминологии, принятой в статистике):
· эмпирического коэффициента корреляционной связи (коэффициент Фехнера);
· коэффициента ассоциации;
· коэффициента взаимной сопряженности Пирсона и Чупрова;
· коэффициента контингенции;
· рангового коэффициента корреляции Спирмана и Кендала;
· линейного коэффициента корреляции;
· корреляционного отношения;
· индекса корреляции;
· бисериального коэффициента корреляции.
Список предложенных различными учеными мер связи эти не исчерпывается. В работе [Гласс, Стенли] приведена классификация мер связи, в которой в качестве классификационного признака использовались сочетания типов измерения обоих признаков. Выделено 10 сочетаний (табл. 2.1).
Таблица 2.1
Типы измерения двух признаков
| Шкала второго признака | ||||
| Шкала первого признака | дихотомическая наименований | дихотомическая в предположении нормального распределения | порядковая | интервальная или отношений |
| дихотомическая наименований | A | |||
| дихотомическая в предположении нормального распределения | B | E | ||
| порядковая | C | F | H | |
| интервальная или отношений | D | G | I | J |
К табл. 2.1 необходимо дать следующие пояснения. Дж.Гласс и Дж. Стенли различают четыре типа измерения переменных:
1. Измерения в дихотомической шкале наименований (фиксируется наличие или отсутствие какого-либо качества). Данные могут быть представлены как 0 и 1, интерпретируемые как код, например: мужчина – 1, женщина – 0.
2. Измерения в дихотомической шкале наименований в предположении нормального распределения. Предполагается, что более полные методы измерения могли бы обеспечить приблизительно нормальное распределение случайной величины, но рассматриваемые данные говорят лишь о том, будет ли объект занимать положение выше (код 1) или ниже (код 0) некоторой точки в этом нормальном распределении.
3. Измерения в порядковой шкале. Данные представляют собой последовательные несвязанные ранги.
4. Измерения в шкалах интервалов или отношений.
Второе замечание – в своей классификации Дж.Гласс и Дж. Стенли не различают факторных и результативных признаков, оно проявляется на следующем этапе анализа меры их связи.
Результатом классификации является десять типов измерения двух признаков, условно обозначенные буквами A, B, C, D, E, F, G, H, I, J (перечислены по возрастанию совместного уровня измерений признаков). Эта классификация, во-первых, помогает разобраться в большом числе различных мер связи, во-вторых, значительно облегчает выбор подходящей меры. Например: хотя один из признаков (или оба) измерены по “высокой” шкале, ввиду недостаточного объема выборки (подвыборок) или же по причине содержательного характера (наличие на шкале признака одной или даже нескольких реперных точек, разделяющих выборку на подвыборки) необходимо или выгодно перейти к более “низкой” шкале измерения.
Приведем наиболее распространенные меры связи, причем начнем их анализ не с самых “простых”, отвечающих низким шкалам измерения, а, напротив, с самых “высоких”.
Коэффициент корреляции Пирсона
Самый известный, изучаемый в курсе высшей математики и во всех курсах статистики – коэффициент корреляции Пирсона RXY. Для его определения необходимо, чтобы оба признака были измерены по абсолютной, интервальной шкале измерения или шкале отношений – тип J (допускается также дискретная шкала подсчетов), причем предполагается нормальное распределение (в последнем случае – условно-нормальная, ибо переменная не является непрерывной) не только каждого из них, но и совместное нормальное распределение двух переменных.Если гипотеза о нормальном распределении каждой переменной не подтверждается, статистический вывод об уровне значимости оценки силы связи переменных по величине выборочного коэффициента корреляции может оказаться неверным.
Другое ограничение относится к характеру связи, оцениваемой коэффициентом корреляции Пирсона – оценивается сила линейнойсвязи. Но связь не обязательно должна быть таковой. Простой пример: пусть две переменные x и y связаны функционально уравнением x2+у2=1. Геометрический образ, отвечающий этому уравнению – окружность. Если на график нанести точки, взятые случайным образом с этой окружности, то образуется “облако” точек, которые, вне всякого сомнения, упорядочены, т.е. случайные переменные связаны. В то же время выборочный коэффициент корреляции Пирсона, показывающий силу связи случайных переменных X и Y (мы специально обозначаем их другими символами, чтобы отличить от детерминированных переменных x и y), окажется близкой к нулю. Поэтому часто, говоря о корреляции “по Пирсону”, добавляют: мералинейной связипеременных.
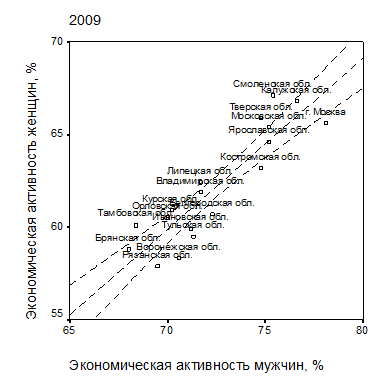
Лучший способ оценить характер связи признаков – графический. Приведем пример. На рис. 2.1 представлено графическое отображение связи экономической активности мужского и женского населения регионов Центрального федерального округа, с одной стороны, городского и сельского, с другой, в виде соответствующих им точек (хi, yi), i = 1, ..., n на плоскости XY (так называемые диаграммы рассеяния, или корреляционные диаграммы).
| а |
|
| б |

|
| Рис. 2.1. Корреляционные поля показателей экономической активности населения регионов ЦФО: а – мужчин и женщин; б – городского и сельского населения. Пунктиром обозначены линии регрессии и 90%-е доверительные границы для средних значений показателей |
Как видно из диаграмм рассеяния рис. 2.1, для обеих пар переменных, измеренных по абсолютной шкале, наблюдается ярко выраженная положительная линейная корреляционная связь – для пары “мужчины” – “женщины” более тесная, менее тесная – для пары “город” – “село”.
Термин “положительная корреляция” отражает тенденцию увеличения значений одной переменной с ростом другой, для отрицательной корреляции, напротив, характерно уменьшение значений одной переменной с увеличением другой. Утверждение симметрично, т.е. обе переменные равнозначны, их подразделение на факторный и результативный признаки не предусматривается.
Численно сила линейной связи характеризуется выборочным коэффициентом корреляции, определяемым по формуле
R = 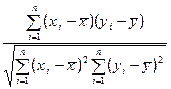 , (2.1)
, (2.1)
где 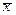 и
и 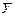 – средние значения переменных, а где n – объем выборки. Если абсолютная величина выборочного коэффициента корреляции ½R½ близка к 1, то это является основанием полагать сильную линейную зависимость между переменными. В приведенном примере корреляции переменных на рис. 2.1 значения выборочного коэффициента корреляции составляют R=0,896 для пары “мужчины” – “женщины” и R=0,593 для пары “город” – “село”.
– средние значения переменных, а где n – объем выборки. Если абсолютная величина выборочного коэффициента корреляции ½R½ близка к 1, то это является основанием полагать сильную линейную зависимость между переменными. В приведенном примере корреляции переменных на рис. 2.1 значения выборочного коэффициента корреляции составляют R=0,896 для пары “мужчины” – “женщины” и R=0,593 для пары “город” – “село”.
Если есть уверенность в том, что распределения каждой из двух переменных не противоречат нормальному закону, то с учетом объема выборки оценивается статистическая значимость найденного значения выборочного коэффициента корреляции, т.е. вероятность a ошибки I рода – ошибки отклонения нулевой гипотезы об отсутствии корреляции, когда она верна. Для рассматриваемого примера уровень значимости выборочного коэффициента корреляции (обычно говорят просто – уровень значимости корреляции) высок для обоих пар переменных: a не более 0,0005 для пары “мужчины” – “женщины” и a=0,012 для пары “город” – “село” при объеме выборок 18 и 17 соответственно. Проверка с помощью критерия Колмогорова-Смирнова показала, что основания сомневаться в нормальности их одномерных распределений нет.
Не противоречит гипотезе о совместном нормальном распределении пар переменных и характер распределения точек на обеих диаграммах рассеяния (рис. 2.1) – “облака” точек характеризуются их сгущением в центральной части и более редким расположением на периферии.
Итак, по результатам визуального просмотра диаграмм рассеяния и по результатам вычислений делаем вывод: по полной выборке объемом 18 регионов ЦФО можно с уверенностью утверждать, что в среднем те регионы, которые характеризуются большими значениями экономической активности мужчин, будут характеризоваться большими значениями экономической активности женщин. Ошибка этого утверждения весьма мала: отсутствие такой корреляции возможно менее чем в пяти случаях из 10000 для пары “мужчины” – “женщины”. Аналогично, для пары “город” – “село” по усеченной выборке объемом 17 регионов ЦФО (без г. Москвы) можно с надежностью 98,8% утверждать, что в среднем те регионы, которые характеризуются большими значениями экономической активности городского населения, будут характеризоваться большими значениями экономической активности сельского населения.
Столь подробно мы останавливаемся на важнейшем случае линейной корреляции и ее оценке с помощью коэффициента корреляции Пирсона, чтобы показать возможные ошибки при анализе двух признаков.
Наиболее часто встречающейся ошибкой является признание так называемой псевдокорреляции истинной. Это случается тогда, когда выборка не однородная, содержит смесь двух подвыборок. Классический пример псевдокорреляции приведен в сборнике задач по теории вероятностей и математической статистике, в которой анализируется количество телевизионных точек и численность населения в десяти городах США. Наряду с девятью городами с населением менее 100 тыс. человек в выборку входил Нью-Йорк с населением 802 т. человек (по данным 1953 года). Понятно, что эта выборка непригодна для подобного анализа: если выборочный коэффициент корреляции между рассматриваемыми показателями для 10 городов R=0,995, т.е. налицо сильная положительная линейная корреляционная связь между численностью населения и количеством телевизионных точек, то для девяти малых городов – только 0,403, т.е. положительная корреляционная связь имеется, но она довольно слабая. Первая корреляция поэтому носит название “псевдокорреляция”. На диаграмме рассеяния о псевдокорреляции свидетельствует “расслоение” облака точек на ярко выраженные отдельно расположенные группы.
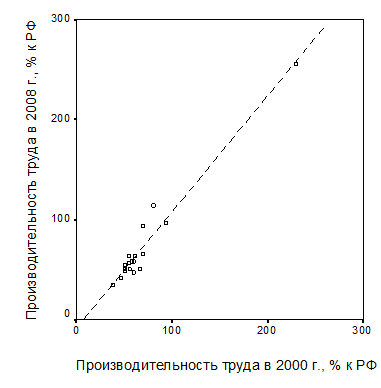
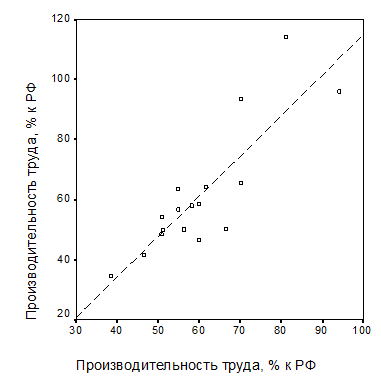
Не исключены подобные ошибки в сфере рынка труда и профессионального образования. В качестве примера рассмотрим диаграмму рассеяния на рис. 2.2.
| а |
|
| б |
|
| Рис. 2.2. Корреляционные поле территориальных индексов производительности труда в регионах ЦФО по данным за 2000 и 2008 гг.: а – полная выборка; б – выборка без г. Москвы |
На этом рисунке представлены корреляционные поля территориальных индексов производительности труда в регионах ЦФО по данным за 2000 и 2008 гг. Видно, что, в отличие от той же пары переменных по полной выборке, характеризующейся очень сильной положительной корреляционной связью с коэффициентом корреляции R=0,976, по усеченной выборке корреляционная связь между ними становится не столь тесной (коэффициент корреляции R=0,852).
Второй класс ошибок – попытка “приписать” корреляционной связи статус причинной. Выводы о причинной связи всегда носят содержательный характер, но никак не могут быть результатом формального анализа силы корреляции. Более того, даже с формальной точки зрения оба коррелирующих признака равноправны, поэтому всегда можно задать вопрос: что первично, а что вторично? Что является причиной, а что следствием? Корреляция – это определенная, ярко выраженная тенденция к одновременному изменению обеих переменных. Другой причиной, по которой нельзя смешивать эти два понятия, является возможное причинное воздействие на обе переменные третьей переменной. Т.е. корреляция между двумя признаками с формальной точки зрения имеется, но она обусловлена их корреляцией с третьим “ведущим” признаком, являющимся для первых двух определяющим. Нужно понимать, что “парные корреляционные характеристики позволяют измерить степень тесноты статистической связи между парой переменных без учета опосредованного или совместного влияния других показателей. Вычисляются (оцениваются) они по результатам наблюдений только анализируемой пары показателей” [Айвазян и др., 1985. С.97].
В ранних книгах по теории и практике математической статистики различию понятий “корреляция” и “причинность” уделялось большое внимание, затем это стало “самим собою разумеющимся фактом” и даже “подзабываться”, поэтому уместно напомнить существо этих понятий.
Наконец, третье замечание касается часто применяемой градации величины коэффициента линейной корреляции как характеристики силы связи (шкала Чеддока). Полагают, что значения, по абсолютной величине большие 0,9 отвечают “весьма высокой” силе связи, от 0,9 до 0,7 – “высокой”, от 0,7 до 0,5 – “заметной”, от 0,5 до 0,3 – “умеренной” и от 0,3 до 0,1 – “слабой” силе связи. При значениях R=1 связь функциональная, при R=0 связь отсутствует. Обоснование такой шкалы – в понятии об индексе (коэффициенте) детерминации, численно равном квадрату выборочного коэффициента корреляции. Это понятие используется в регрессионном анализе; смысл индекса детерминации – доля дисперсии результативного признака, объясняемой влиянием изучаемого признака (одного или нескольких). Граничным значением является величина R=0,7, поскольку тогда R2»0,5, т.е. при показаниях тесноты связи ниже 0,7 величина индекса детерминации всегда будет меньше 50%. Таким образом, если R>0,7, то связь результативного признака с факторным может считаться высокой.
Но в этих рассуждениях не учитывается объем выборки n. Поэтому представляется, что более корректной является оценка силы связи двух количественных переменных по t-критерию, величина которого сравнивается с “критическим” значением, зависящим от объема выборки:
t = 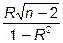 , (2.2)
, (2.2)
где n-2 – число степеней свободы. В табл. 3.2 приведены значения коэффициента корреляции в зависимости от уровня доверительной вероятности (Р=0,95 и Р=0,99) и объема выборки, рассчитанные по t-критерию (таблица с некоторыми изменениями заимствована из книги К. Доерфеля).
Таблица 2.2
Значения коэффициента корреляциипри различныхуровнях значимости (Доерфель К., 1969)
| Объем выборки | Доверительная вероятность | Объем выборки | Доверительная вероятность | Объем выборки | Доверительная вероятность | |||
| n | P=0,95 | P=0,99 | n | P=0,95 | P=0,99 | n | P=0,95 | P=0,99 |
| 1,00 | 1,00 | 0,60 | 0,74 | 0,34 | 0,43 | |||
| 0,95 | 0,99 | 0,58 | 0,71 | 0,31 | 0,40 | |||
| 0,88 | 0,96 | 0,55 | 0,68 | 0,29 | 0,38 | |||
| 0,81 | 0,92 | 0,53 | 0,66 | 0,28 | 0,36 | |||
| 0,75 | 0,87 | 0,51 | 0,62 | 0,25 | 0,33 | |||
| 0,71 | 0,83 | 0,44 | 0,56 | 0,23 | 0,30 | |||
| 0,67 | 0,80 | 0,40 | 0,52 | 0,22 | 0,28 | |||
| 0,63 | 0,77 | 0,36 | 0,47 | 0,20 | 0,25 |
Впервые такая таблица была составлена Р. Фишером и в полном виде приведена в книге Ф. Миллса. Из этой таблицы следует, что при объеме выборки n=25 коэффициент корреляции R=0,52 является значимым на высоком уровне доверительной вероятности 0,99, в то время как это же значение выборочного коэфициента корреляции при объеме выборки n=25 является значимым только на 95%-м уровне доверия, а при меньшем объеме – и вовсе незначимым.
Здесь уместно отметить, что для малых выборок и при значениях линейного коэффициента корреляции R³0,8 для проверки его уровня значимости рекомендуется использовать метод преобразования корреляции, предложенный Р. Фишером, называемое также z-преобразованием Фишера. Это преобразование также позволяет вычислить доверительные границы, кроме того, оно используется в критерии однородности двух или нескольких выборочных коэффициентов корреляции.
В ряде случаев требование близости распределения переменных к нормальному можно выполнить путем их логарифмического преобразования. Это преобразование является «стандартным», когда речи идет об эмпирическом распределении с правосторонней асимметрией, т.е. если среднее арифметическое больше медианы, а медиана больше моды.
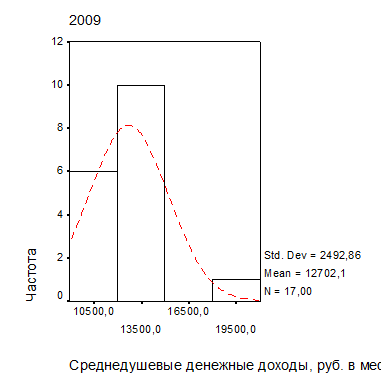
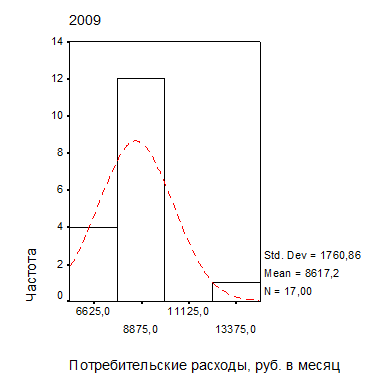
Приведем пример. Как известно, большинство социально-экономических показателей характеризуются распределениями с положительной (правосторонней) асимметрией. Так, из анализа характера гистограмм на рис. 2.3 можно предположить, что распределение среднедушевых денежных доходов и потребительских расходов населения регионов Центрального федерального округа (без г. Москвы) близко к логарифмически нормальному: медианное значение среднедушевых денежных доходов населения 12205,0 руб. меньше среднего арифметического (невзвешенного) 12702,1 руб., а медианное значение потребительских расходов населения 8397,0 руб. на человека меньше среднего арифметического (невзвешенного) 8617,2 руб. на человека.
| а |
|
| б |
|
| Рис. 2.3. Распределение доходов (а) и расходов (б) населения регионов ЦФО (выборка без г. Москвы) |
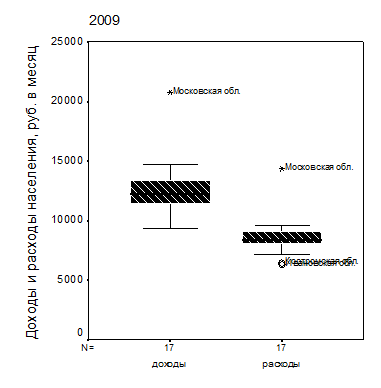
Строго говоря, «выбросом» являются не только данные по г. Москве, а и данные по Московской области: на ящичковой диаграмме рис. 2.4 этот регион отмечен “звездочкой”, но здесь мы исходим из желания сохранить в выборке как можно больше регионов. В противном случае потребовалось бы исключить из выборки также данные по Ивановской и Костромской областям, которые характеризуются пониженными значениями потребительских расходов населения. Есть и еще один довод в пользу логарифмического преобразования, о котором мы скажем несколько позднее.
|
| Рис. 2.4. Распределение доходов (а) и расходов (б) населения регионов ЦФО (выборка без г. Москвы) |
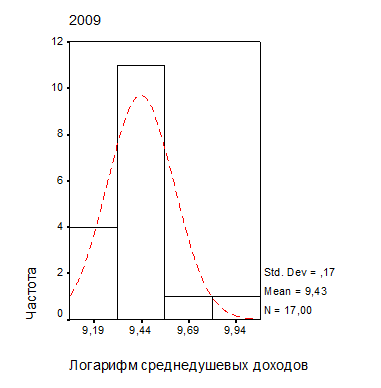
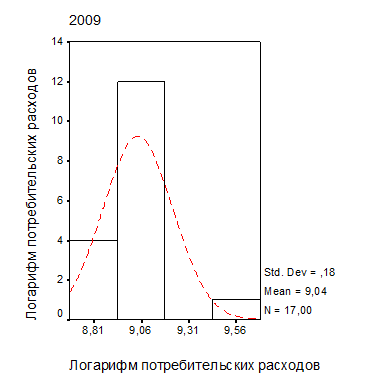
Как следует из рис. 3.5, после логарифмического преобразования переменных распределение становится более симметричным; проверка с помощью критерия Колмогорова-Смирнова также показала эффективность такого преобразования.
| а |
|
| б |
|
| Рис. 2.4. Распределение доходов (а) и расходов (б) населения регионов ЦФО после логарифмического преобразования (выборка без г. Москвы) |
Если вычислить коэффициент линейной корреляции для преобразованных переменных, распределение которых ближе к нормальному, чем исходных показателей, то его значение составит величину R=0,967, статистическая значимость которого не хуже 0,0005.
Приведенный пример имеет и другое следствие. В экономической теории и практике важной характеристикой является эластичность. Различают дуговую и мгновенную эластичность. Дуговая эластичность – это отношение относительного приращения результативного показателя к относительному приращению предиктора – объясняющего показателя, а мгновенная эластичность – это логарифмическая производная. Существует лишь одна функция, для которой мгновенная эластичность постоянна во всем диапазоне изменения предиктора – это степенная функция вида
Y = b0 × x b1. (2.1)
Математически мгновенная эластичность равна показателю степени модели (2.1):
Э Y/x = b1 x. (2.2)
В случае же линейной функции
Y = b0 + b1 x (2.3)
обычно рассчитывают дуговую эластичность в центре диапазона изменения предиктора
Э Y/x = b1 xср / Yср,(2.4)
где xср и Yср – средние значения переменных.
Если положить x=lnС и Y=lnD, где С – потребительские расходы, а D – среднедушевые денежные доходы, то МНК-оценку мгновенной эластичности можно найти по уравнению линейной регрессии
lnD = b0 + b1 lnС. (2.5)
В рассматриваемом случае имеет место следующая линейная регрессия:
lnD = -0,535 + 1,015 lnС, (2.6)
откуда получаем, что мгновенная эластичность потребительских расходов по денежным доходамЭY/x=1,015. Иначе говоря, при увеличении среднедушевых денежных доходов населения регионов ЦФО (без г. Москвы) на 1% потребительские расходы увеличиваются на 1,015%.
Ранговые меры связи двух признаков
Естественно, диаграммы рассеяния удобнее изучать по исходным (непреобразованным) показателям. При этом вовсе не обязательно для определения силы связи стремиться к их преобразованию к распределению, близкому к нормальному, а затем вычислять коэффициент корреляции Пирсона. Есть другой, значительно более простой путь: использовать так называемые непараметрические методы статистики, позволяющие измерить силу связи как между количественными показателями, характер распределения которых отличается от нормального, так и между качественными показателями с упорядоченными уровнями (тем самым мы переходим к следующему типу измерения двух признаков – типу I по табл. 2.1).
В основу непараметрических методов положен принцип ранжирования (нумерации) значений статистического ряда. Различают несвязанные и связанные (объединенные) ранги. Во втором случае имеются одинаковые значения признака, которым присваивается равные ранги, равные среднему значению порядкового номера этих наблюдений (связанные ранги могут быть и дробными). Варианты обоих признаков располагают по возрастанию и сравнивают ранги. Если между признаками наблюдается положительная корреляция, то с увеличением ранга одного признака (неважно, какого именно) будет иметь место тенденция к увеличению рангов другого признака. И наоборот, если с увеличением ранга одного признака наблюдается тенденция к уменьшению рангов другого признака — корреляция отрицательная. Понятно, что монотонное преобразование переменных не меняет ранги наблюдений, поэтому характер распределения признаков не имеет значения.
Коэффициенты корреляции, основанные на использовании рангов, были предложены английским психологом К. Спирманом еще в 1904 г. (ранговый метод впервые применил Ф. Гальтон) и статистиком М. Кендаллом (1955 г.). Первый носит название “коэффициент ранговой корреляции Спирмана” (r), второй – “тау Кендалла” (i). Мы не приводим расчетные формулы, поскольку все пакеты анализа данных, в том числе рекомендуемый нами пакет статистических программ анализа данных общественных наук SPSS Base содержит соответствующую процедуру их расчета; интересующиеся могут воспользоваться любым справочником или учебником по математической статистике. Важно помнить, что обе меры силы связи, как и коэффициент корреляции Пирсона, могут находиться в пределах ½rÎ[0, 1], ½iÎ[0, 1]: значение 0 отвечает отсутствию связи, 1 – положительной и -1 – отрицательной связи максимальной силы.
Заметим, что если две переменные нормально распределены, то между линейным коэффициентом корреляции (т.е. коэффициентом корреляции Пирсона R) и ранговым коэффициентом корреляции Спирмана r имеется зависимость
r = 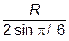 . (2.7)
. (2.7)
Если обратиться к рассмотренному выше примеру, то величина рангового коэффициента корреляции Спирмана для рассматриваемой пары показателей (среднедушевые денежные доходы и потребительские расходы населения регионов ЦФО) составляет 0,951; естественно, для логарифмически преобразованных показателей мы получаем то же значение коэффициента r, весьма близкое к значению коэффициента Пирсона R=0,967 для преобразованных переменных с распределением, более близким к нормальному.
Имеется связь и между ранговыми мерами силы связи. При достаточно большом объеме выборки между значениями рангового коэффициента корреляции Спирмана r и тау Кендалла (i) соблюдается примерное соотношение:
i/r »2/3. (2.8)
В ряде работ отмечается, что вычисление тау Кендалла является более трудоемким по сравнению с расчетом рангового коэффициента корреляции Спирмана. В то же время коэффициент Кендалла обладает лучшими статистическими свойствами (возможно приближенное построение доверительных интервалов), имеется возможность его использования в многомерном корреляционном анализе. В рассматриваемом случае тау Кендалла равняется i=0,868, и соотношение (3.8) не выдерживается, поскольку объем выборки мал (n=17).
| <== предыдущая страница | | | следующая страница ==> |
| Введение в клиническую терминологию | | | Предприятие в условиях рыночной экономики |
Дата добавления: 2014-10-02; просмотров: 421; Нарушение авторских прав

Мы поможем в написании ваших работ!