Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Система типов языка C#. Встроенные типы
Все типы C# подразделяются на две основные категории: типы значений и ссылочные типы.
Переменные типа значений содержат данные, переменные ссылочного типа хранят адреса ячеек памяти (ссылки), в которых размещены соответствующие данные. Для данных типов значений память отводится в момент их объявления и такие данные называют статическими. Для данных, на которые ссылаются переменные ссылочных типов, память выделяется по специальным запросам уже в процессе выполнения программы. Поэтому такие данные называются динамическими.
Типы данных принято также подразделять на простые и сложные в зависимости от того, как устроены их данные. Значения простых (скалярных) типов едины и неделимы. Сложные типы характеризуются способом структуризации данных – одно значение сложного типа состоит из множества значений данных, организующих сложный тип. Примером сложного типа данных является массив.
Наконец, типы делятся на встроенные и пользовательские, т.е. типы, определенные программистом. Встроенные типы изначально принадлежат языку программирования и составляют его базис. В основе системы типов любого языка программирования всегда лежит базисная система типов, встроенных в язык. Пользовательские типы объявляются (конструируются) программистом на основе встроенных типов. Но правила создания таких типов являются базисными, встроенными в язык.
В языке C# имеется богатый набор встроенных типов.
· логический тип,
· большое число числовых типов,
· символьный
· строковый
· объектный тип.
Среди этих типов есть простые и сложные, типы значений и ссылочные типы.
2.2.1. Числовые типы данных
Большинство простых типов являются целочисленными, т.е. предназначенными для работы с целыми числами. Причина существования нескольких целочисленных типов вместо одного заключается в необходимости предоставить программисту возможность использовать различные диапазоны целочисленных значений, в зависимости от особенностей реализуемого алгоритма. Каждый из целочисленных типов задает свой размер ячейки – число байт (и, соответственно, бит), отводимых для хранения значений. В ячейке из N бит (N / 8 байт) можно записать 2N различных двоичных кодов, представляющих такое же количество целых чисел. Соответствие между этими кодами и представляемыми ими числами устанавливается двумя альтернативными способами.
Первый способ основан на предположении, что все числа являются неотрицательными. В этом случае минимальным является число 0, представляемое цепочкой из N нулей, а максимальным – число 2N – 1, представляемое цепочкой из N единиц.
Второй способ позволяет представлять как отрицательные, так и неотрицательные значения. В этом случае цепочки бит, начинающиеся с нуля сопоставляются неотрицательным значениям, а начинающиеся с единицы – отрицательным. Число 0 по-прежнему изображается цепочкой из N нулей, максимальное положительное число оказывается равным
2N-1 – 1, а минимальное отрицательное – равным –2N-1.
Все целочисленные типы перечислены в табл. 2.
Таблица 2.
Целочисленные типы данных
| Тип | Число байт | Допустимые значения |
| sbyte | от –128 до 127 | |
| byte | от 0 до 255 | |
| short | от –32768 до 32767 | |
| ushort | от 0 до 65535 | |
| int | от –2147483648 до 2147483647 | |
| uint | от 0 до 4294967295 | |
| long | от –9223372036854775808 до 9223372036854775807 | |
| ulong | от 0 до 18446744073709551615 |
Символы u в начале имен некоторых переменных являются сокращением от слова unsigned (беззнаковый), которое указывает на то, что хранить отрицательные числа в переменных этих типов нельзя. Символ s в названии первого из байтовых типов является сокращением от слова signed (знаковый) и, напротив, говорит о том, что для переменных этого типа допустимы как неотрицательные, так и отрицательные значения.
Целочисленные значения, присутствующие в тексте программы, называются числовыми литералам. Правила записи числовых литералов совпадают с привычными правилами записи целых чисел. В тех редких случаях, когда требуется уточнить целочисленный тип, к которому следует отнести литерал, в записи литералов используют буквенные суффиксы. Следует отметить, что уточнения в виде суффиксов можно применять только к типам uint, long и ulong. Соответствующие суффиксы имеют вид U, L, LU или UL. Эти символы можно набирать как в верхнем, так и в нижнем регистре. Например,
long k = 10L;
uint m = 10u;
ulong n = 10Ul;
Литералы целых типов могут записываться в шестнадцатеричной системе счисления с использованием префикса 0x Например, число 1000 может быть записано как 0x3E8 с использованием префикса x и 16-ричных цифр.
Для хранения вещественных значений с плавающей точкой доступны переменные типов float и double. Вещественные значения хранятся в так называемой полу-логарифмической форме, т.е. в виде ±m*2p. Множитель m называется мантиссой числа, а показатель степени двойки p – его порядком. Для обеспечения однозначности выбора порядка числа на мантиссу накладывается условие нормированности. Обычно оно состоит в задании диапазона допустимых значений мантиссы (1; 0.5]. В таблице 3 представлены оба эти типа данных.
Таблица 3.
Вещественные типы данных
| Тип | Число байт | Допустимые значения |
| float | от -3.4×1038 до -1.5×10-45 и от 1.5×10-45 до 3.4×1038 | |
| double | от -1.7×10308 до -5.0×10-324 и от 5.0×10-324 до 1.7×10308 |
Литералы вещественного типа имеют две формы записи – с фиксированной и с плавающей точкой. В первом случае вещественное число записывают с использованием точки в качестве разделителя целой и дробной части. Например, 5.25 или –234.5.
Во втором случае число записывается с использованием множителя в виде степени числа 10, т.е. фактически в виде ±m*10p. При этом не накладывается никаких ограничений на возможные варианты выбора значений пары m и p. Например, одно и то же значение 234.5 может быть записано так 23.45e1 или 2345e-1. Обычно такая форма записи используется для представления очень больших или очень малых величин.
Так же как и целых литералов в записи литералов вещественного типа можно использовать буквенные индексы – f для типа float и d для типа double. Впрочем, для типа double буквенный суффикс можно не указывать.
Еще одним числовым типом является тип decimal. Переменная этого типа позволяет хранить значения в виде ±m*10e.
2.2.2. Булевский и символьные типы данных
В C# имеются два простых типа, предназначенных для работы с нечисловыми данными: булевский boolи символьныйchar.
Таблица 4.
Нечисловые простые типы данных
| Тип | Число байт | Допустимые значения |
| bool | true или false | |
| char | Символы Unicode |
Данные булевского типа обычно используются в программах для проверки тех или иных условий. Литералы булевского типа – это ключевые слова true и false.
Замечание. В языке C# не определено преобразование булевских значений в числовые, например, true в 1, а false в 0, как это сделано в C++.
Литералы символьного типа имеют вид символа, заключенного в апострофы. Например, 'A', '8', '+'. Однако, такой способ записи пригоден только для символов, допускающих непосредственное представление. Более универсальным является их представление с помощью их числовых кодов, т.е. порядковых номеров символов в таблице Unicode.
Unicode – это пронумерованный набор символов, включающий символы латинского алфавита, символы национальных алфавитов (в том числе, русского), цифры, знаки препинания, целый ряд специальных символов. Такой набор называется кодовой таблицей. Символы набора Unicode пронумерованы целыми числами из диапазона от 0 до 65535, т.е. их общее число равно 65536. Первые 128 символов Unicode совпадают с символами стандарной части хорошо известной таблицы ASCII.
Представление с помощью числовых кодов состоит из символов «0x», за которыми следует шестнадцатеричный код. Например, вышеприведенные символы можно записать в виде: '0x0041', '0x56', '0x02b'.
Наконец, для ряда символов, имеющих специальное назначение, используется представление в виде управляющих (escape) последовательностей. В таблице 5 для справки перечислены все управляющие последовательности.
Таблица 5.
Управляющие последовательности
| Управляющая последовательность | Получаемый символ | Unicode-значение |
| \’ | Символ одиночной кавычки | 0x0027 |
| \" | Символ двойной кавычки | 0x0022 |
| \\ | Символ обратной косой черты | 0х005С |
| \0 | Отсутствие символа | 0x0000 |
| \a | Символ предупреждения (звуковой сигнал) | 0x0007 |
| \b | Символ возврата | 0x0008 |
| \f | Символ перевода страницы | 0x000с |
| \n | Символ новой строки | 0х000А |
| \r | Символ возврата каретки | 0x000D |
| \t | Символ горизонтальной табуляции | 0x0009 |
| \v | Символ вертикальной табуляции | 0x000В |
В столбце "Unicode-значение" данной таблицы приведены шестнадцатеричные значения символов в том виде, в котором присутствуют в наборе символов Unicode.
2.2.3. Строковый тип данных
Тип string является ссылочным, поэтому переменные этого типа хранят лишь адреса строк. Сами же строки являются динамическими структурами и размещаются в памяти уже в процессе выполнения программы. Длина строки ограничивается только размером доступной оперативной памяти. В памяти компьютера строки представляются цепочками кодов образующих их символов, завершающихся признаком конца строки – управляющей последовательностью \0.
Строковые литералы записываются как последовательности символов, заключенные в двойные кавычки (в отличие от одиночных символов!). Таким образом, если 'A' – это символ, то "A" – это строка из одного символа. Примеры строк:
"Hello, World!" или "2*2=4"
Строки могут включать в себя управляющие последовательности. Например:
"С:\\Temp\\MyDir\\MyFile.doc"
или
"Роман \"Три мушкетера\" – его любимая книга, а д\'Артаньян – любимый герой".
Существует возможность отказаться от использования в строках управляющих последовательностей или, как говорят, задавать строки дословно (verbatim). Для этого достаточно предварить строку символом @. После этого можно будет, в частности включать в строковый литерал символы переноса строк и табуляции. Например:
@"С:\Temp\MyDir\MyFile.doc"
А вот такую строку
@"Возможные значения:
вариант 1
вариант 2"
при использовании управляющих последовательностей пришлось бы записать в виде:
"Возможные значения:\n\t вариант 1\n\t вариант 2"
Единственным исключением является управляющая последовательность для символа двойных кавычек, которая должна обязательно указываться во избежание окончания строки.
В следующем примере приводится простой код, который объявляет две переменные, присваивает им значения и затем выводит эти значения на экран.
Пример 2.1Использование переменных простых типов
Листинг 2.1. Использование переменных простых типов
using System;
namespace ConsoleApplication5
{
class Program
{
static void Main(string[] args)
{
int k;
string myString;
k = 17;
myString = "\"моеЦелое\" равно ";
Console.WriteLine("{0} {1}.", myString, k);
Console.ReadKey();
}
}
}
На рис. 2.1 показан результат, который должен получиться.
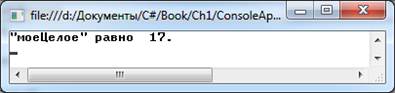
Рис. 2.1. Результат выполнения приложения
Код программы выполняет следующее: объявляет две переменных; присваивает этим двум переменным значения; выводит значения этих двух переменных на консоль.
Объявление переменных происходит в следующей части кода:
int k;
string myString;
В первой строке объявляется переменная типа int с именем k, а во второй — переменная типа string с именем myString. В следующих двух строках кода осуществляется присваивание значений:
k = 17;
myString = "\"моеЦелое\" равно ";
Здесь переменным присваиваются два фиксированных значения с помощью операции присваивания =. Переменной kприсваивается целочисленное значение 17, а переменной myString — строка "myString" (вместе с кавычками).
2.2.4. Объектный тип данных
Типы данных в языке С# имеют достаточно сложное устройство. Во-первых, все они, как встроенные, так и пользовательские, являются классами. Это означает, что с каждым из них, кроме множества возможных значений, связано множество функций (методов) для работы с данными этого типа. Во-вторых, типы С# образуют иерархию, в основании которой находится корневой тип. Таким корневым типом в C# является тип object. Методы этого типа являются базовыми и доступны для любого другого типа данных.Тип object является ссылочным типом. Более подробное знакомство с этим типом отложим до главы 5, посвященной описанию классов.
| <== предыдущая страница | | | следующая страница ==> |
| Переменные | | | Преобразование типов |
Дата добавления: 2014-10-10; просмотров: 870; Нарушение авторских прав

Мы поможем в написании ваших работ!