Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
УПРАВЛЕНИЕ ПОТОКОМ ДАННЫХ
7.1 Ключевые (основные) вопросы (моменты)
— управление потоком данных;
— граф потока данных (токены);
7.2 Текст лекции
7.2.1 Управление по потоку данных
Другой механизм, предложенный в 60-х годах Р. Карпом и Г. Миллером (R.M. Karp, G.L. Miller), получил название управления потоком данных. Основная идея состоит в том, что система управления вычислительным процессом фиксирует порядок вычислений аргументов и инициализирует выполнение команды, когда все необходимые аргументы для нее готовы. Таким образом, команда выполняется в том случае, если для этого создались все необходимые условия, то есть на соответствующую вершину информационного графа поступили все необходимые операнды. При наличии достаточных аппаратных средств одновременно может обрабатываться произвольное число готовых к исполнению инструкций, при этом последовательность, в которой выполняются команды, уже не является детерминированной, а зависимость по данным учитывается автоматически.
Отличия обработки, управляемой потоком данных от обработки фон-неймановского типа состоят в следующем:
· Операцию с имеющимися операндами можно выполнять независимо от состояния других операторов, то есть появляется возможность одновременного выполнения множества операций (параллельная обработка).
· Обмен данными между операторами четко определен, поэтому отношение зависимости между операциями обнаруживается легко (функциональная обработка).
· Управление вычислительным процессом не нуждается в счетчике команд и является полностью децентрализованным (распределенная обработка).
При использовании механизма управления потоком данных списочная форма представления информационного графа, в отличие от рассмотренного выше традиционного фон-неймановского механизма, должна отражать не единственную последовательность операторов, а общую структуру алгоритма. Программа представляется как совокупность командных шаблонов, последовательность реализации которых определяется в момент получения результатов от выполненных на предыдущем шаге операторов. Командный шаблон может быть задан следующим образом:
S = (G, X, D1,…Dn, R1,…Rn),
где G – операция, отражающая выполняемую функцию; X – условия срабатывания вершины информационного графа (спусковая функция); D1,…Dn – поля операндов, заполняемые по мере выполнения предшествующих операторов, которые используются как для выполнения операции G, так и для вычисления спусковой функции X ; R1,…Rn – поля назначения, указывающие какому шаблону должен быть передан результат выполнения операции G. Любые готовые шаблоны могут выполняться одновременно, а их готовность к выполнению определяется аппаратными средствами в процессе выполнения программы.
Реализация такой идеи приводит к появлению понятия командной ячейки, которая должна хранить код операции, непосредственные операнды с их битами готовности и адресные поля, указывающие поля операндов других командных ячеек, в которые отправляется результат данной операции. Поскольку результат одной операции может активировать несколько других командных ячеек, то для формирования дополнительных копий данных вводится дополнительная операция пересылки, которая имеет один операнд и два адресных поля отсылок, что позволяет, комбинируя командные ячейки пересылок реализовывать отправку поля данных в несколько командных ячеек.
Наиболее распространенной формой представления программы для машин потоков данных является граф потока данных (dataflow graph), который может быть представлен в памяти системы в виде таблицы (рис.5.2). В графе потока данных, основу которого составляет информационный граф, для обозначения перемещений данных используются специальные маркеры доступа (токены), а дополнительно к операционным вершинам вводятся вершины пересылки L, слияния V и ветвления TF. Каждая из вершин пересылки осуществляет копирование входных данных, поступающих на единственный вход этого узла и их вывод через две выходные дуги; каждая из вершин слияния представляет собой узел, в котором данные с одного из двух входов без изменения подаются на выход.
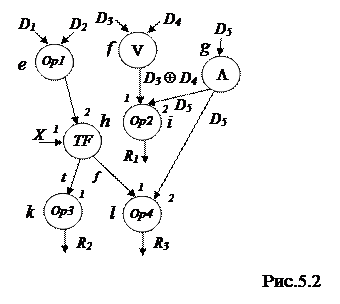 |
| Код операции | Поля операндов | Адрес назначения | Тег | ||
| e | Op1 | D1 | D2 | h2 | 1 │1 |
| f | V | D3 | D4 | i1 | 1 │1 |
| g | L | D5 | ─ | i2 , l2 | 1 │1 |
| h | TF | X | k1 , l1 | 1 │0 | |
| i | Op2 | R1 | 0 │0 | ||
| k | Op3 | ─ | R2 | 0 │1 | |
| l | Op4 | R3 | 0 │0 |
Вершины ветвления, соответствуя командам условного перехода в системах с традиционной архитектурой, используются для описания нелинейных фрагментов программы, и представляют собой узлы с двумя входами, на один из которых подается токен данных, а на другой – токен управления Х. В зависимости от значения токена на управляющем входе токен результата передается на один из двух выходов: если значение истинно (true), то результат передается на левый выход, при ложном (false) значении – на правый. Таким образом, инструкция ветвления содержит поле кода операции, поля операнда и управляющего признака Х, флаги готовности предыдущих двух полей, а также поля назначения. Формат инструкции слияния (пересылки) включает поле кода операции, операнда и флага его готовности, а также поле (поля) назначения.
В общем виде машина потоков данных содержит память, хранящую шаблоны инструкций, устройство обработки, состоящее из множества многофункциональных или специализированных процессорных элементов, выполняющих активированные инструкции, арбитражную (селекторную) и распределительную сети. Арбитражная сеть используется для отслеживания и передачи в устройство обработки готовых (активированных) командных ячеек, назначение распределительной сети - пересылка и размещение полученных результатов в полях операндов других командных ячеек.
Таким образом, если все операнды присутствуют в инструкции, то есть их флаги в командной ячейке памяти установлены в единицу, инструкция поступает в селекторную часть, при этом флаги сбрасываются, а арбитражная сеть передает инструкцию на исполнение в один из процессорных элементов устройства обработки. Сам код операции может не передаваться, а использоваться для подключения к командной ячейке соответствующего операционного устройства. В другом варианте код операции включается в пакет готовой к исполнению инструкции и направляется на один из многофункциональных процессорных элементов, формирующих результат. В обоих случаях результат исполнения вместе с адресом назначения (или именем инструкции получателя), взятым из переданной на обработку инструкции, передается в распределительную сеть, которая направляет его в соответствующую командную ячейку памяти. Данный процесс продолжается до получения окончательного результата.
Если результат инструкции должен быть направлен нескольким командным ячейкам, то может предусматриваться специальная команда размножения, включающая произвольное число адресов назначений. Память шаблонов инструкций (командных ячеек) может быть организована по ассоциативному принципу, тогда кроме указанных выше полей каждая командная ячейка должна содержать поле собственного имени. Передача операндов между шаблонами инструкций осуществляется по значению, а не по ссылке, что приводит к тому, что память в машине потоков данных уже не рассматривается как пассивное хранилище данных.
В некоторых системах память инструкций и память токенов данных разделены, а токен результата кроме адреса получателя содержит тег. В этом случае для выборки из памяти и передачи на исполнение очередной инструкции, токен результата предварительно направляется в специальный узел подбора, который производит поиск в памяти токенов идентичного адреса и тега. Если такого адреса и тега в памяти токенов не обнаружено, то поступивший токен просто запоминается в этой памяти, иначе найденный токен или оба токена с одинаковыми значениями адреса назначения и тега передаются в узел, который выбирает из памяти шаблонов и передает на исполнение инструкцию с тем же именем.
Управление потоком данных не накладывает каких-либо ограничений на порядок выполнения операторов, за исключением ограничений, присущих структуре самого алгоритма, и позволяет достичь предельного распараллеливания. Архитектура машины потоков данных рассчитана на параллельное выполнение задач, в которых отсутствует параллелизм объектов и которые, следовательно, не могут быть эффективно решены с помощью векторно-конвейерных или матричных систем. С другой стороны, обработка векторов и матриц на потоковых машинах может оказаться неэффективной, если вся структура, объединяющая несколько элементов данных, будет рассматриваться как один объект. Это будет означать невозможность начала выполнения очередной инструкции для обработки этой структуры до завершения обработки всех элементов структуры предыдущей инструкцией.
Развитие идеи управления потоком данных наталкивается на решение ряда вопросов, связанных с синхронизацией. Простейший и наиболее очевидный из конфликтов синхронизации – попытка одновременной записи результатов нескольких команд в одну ячейку памяти, другая проблема – синхронизация записи-чтения при обработке структур. Решение подобных вопросов должно осуществляться как на уровне аппаратного обеспечения, так и путем разработки новой модели программирования, в которой, например, вместо операции присваивания, сохраняющей результат в ячейке памяти, ассоциированной с переменной, используется операция передачи этого результата в качестве операнда ожидающим его командам с последующей их активизацией.
Несоответствие стиля программирования, требуемого для машин потоков данных, традиционным стилям, к которым привыкли программисты, существенно тормозит их развитие. Например, архитектура машины потоков данных, ориентированная на язык программирования с однократным присваиванием не обладает свойством повторной входимости, позволяющим однократно использованный шаблон инструкции использовать повторно, что исключает циклы, необходимые для организации итерационных вычислений.
Рассмотрим граф потока данных (рис.5.3), соответствующий циклу for системы с традиционной архитектурой:
for (i =0; i <= n; i++) a+= b.
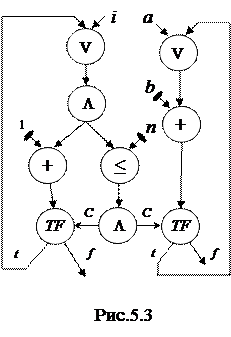 |
При организации циклов возможно возникновение ситуации, когда новые токены данных поступают на входы вершин до поглощения предыдущих на предшествующем цикле итерации. Для предотвращения возникающей при этом неопределенности используются различные механизмы. Одним из наиболее эффективных, обеспечивающих максимальный уровень параллелизма, является механизм копирования инструкций, который предполагает возможность получения копий отдельных участков повторно входимого подграфа. Частичное копирование программного кода позволяет уменьшить затраты времени и памяти по сравнению с получением полных копий подграфа, поглощающих принадлежащие разным итерационным циклам токены данных.
Одним из вариантов частичного копирования является метод раскраски токенов, который предполагает приписывание каждому токену тега, однозначно определяющего номер итерации и степень вложенности цикла. В данном методе на вход каждой вершины графа потока данных может поступать несколько токенов с различными значениями тегов, при этом срабатывание вершины (исполнение инструкции) происходит только при наличии на всех её входах токенов данных с одинаковыми тегами.
Механизмы копирования и раскраски токенов используются в потоковых машинах с динамической архитектурой, в которой возможно формирование новых инструкций и переменных во время выполнения программы. Одна из первых динамических архитектур с окрашенными токенами была создана в Манчестерском университете Гурдом и Ватсоном (J.R. Gurd, I. Watson) в 1980 году. Поддерживая многократное использование шаблонов с разными значениями входных переменных, динамическая архитектура позволяет осуществлять параллельное выполнение отдельных итераций цикла, а также одновременно выполнять все обращения к реентерабельной процедуре.
Другой механизм организации повторной входимости основан на квитировании (подтверждении) исполнения инструкций, что отражается на графе потока данных введением дополнительных дуг квитирования, направленных от вершины-получателя к вершине-источнику токена данных. По этим дугам поступают контрольные токены, сигнализирующие вершине о том, что ее выходной токен уже востребован последующим узлом графа. Несмотря на то, что механизм подтверждения обеспечивает возможность частичного совмещения смежных итерационных циклов, он не позволяет достичь высокого уровня параллелизма, свойственного динамической архитектуре. Кроме того, квитирование исполнения инструкций приводит к удвоению числа дуг и токенов, что усложняет аппаратуру и снижает скорость распространения токенов данных.
Механизм квитирования используется в машинах потоков данных со статической архитектурой, которая впервые была предложена Деннисом (J.B.Dennis) в 1975 году и реализована под его руководством в Массачусетсском технологическом институте (MIT). Эта архитектура допускает присутствие на ребре графа потока данных не более одного токена, что выражается в правиле активизации узла: вершина активизируется, когда на всех ее входных дугах присутствует по токену и ни на одном из ее выходов токенов нет. При этом анализ готовности инструкций к исполнению основан на использовании специальных флагов готовности операндов или счетчиках. Программный код для статической архитектуры машины потоков данных создается на этапе трансляции и в процессе работы не изменяется, то есть новые инструкции, соответствующие новым вершинам графа потока данных, в процессе выполнения программы не создаются.
Рассмотренные выше механизмы управления функционируют на уровне команд, что приводит к большим издержкам при пересылке операндов. Для уменьшения коммуникационных издержек вместо низкоуровневой потоковой обработки отдельных инструкций применяют макропотоковую обработку нитей (потоков), представляющих собой последовательности из нескольких команд. В данной модели вершины графа потока данных уже соответствуют не отдельным командам, а целым фрагментам программы, решающим определенные подзадачи. При этом определение порядка активизации вершин Gi (выявление готовых к исполнению потоков) происходит динамически в процессе вычислений, а последовательность исполнения команд в каждом потоке определена статически на этапе компиляции. Таким образом, макропотоковая модель, называемая крупнозернистой потоковой обработкой (coarse-grained dataflow) совмещает традиционную фон-неймановскую модель вычислений с механизмом активизации потоков, который используется в машинах, управляемых потоком данных.
В настоящее время принцип управления потоком данных используется в специализированных процессорах для обработки сигналов и изображений, а также при реализации суперскалярности в микропроцессорах общего назначения. В потоковых машинах параллелизм не задается явно, а выявляется аппаратными средствами обработки на этапе исполнения инструкций. Реализация данного способа управления оказывается сложной из-за неограниченного роста числа параллельных процессов и резкого усложнения их взаимодействия.
8 Лекция №7
| <== предыдущая страница | | | следующая страница ==> |
| УПРАВЛЕНИЕ ПОСЛЕДОВАТЕЛЬНОСТЬЮ КОМАНД | | | УПРАВЛЕНИЕ ПО ЗАПРОСУ |
Дата добавления: 2014-11-24; просмотров: 739; Нарушение авторских прав

Мы поможем в написании ваших работ!