Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Динамическое программирование. Общая постановка задачи
Динамическое программирование (ДП) – метод оптимизации, в котором процесс принятия решений может быть разбит на ряд шагов. Особенностью его является то, что в отличие, например, от ЛП, который используется для принятия крупномасштабных плановых решений в сложных ситуациях, ДП применяется при решении задач меньшего масштаба. Таких как разработка правил управления запасами и принципов календарного планирования производства, при распределении дефицитных капитальных вложений и др. Задача пошаговой (дискретной) оптимизации формулируется так: определить такое допустимое управление Х, переводящее систему S из состояния S0 в состояние S^, при котором целевая функция
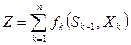 ,
,
принимает max (min) значение, где  - состояние;
- состояние;  - управление.
- управление.
Для ДП характерны следующие правила и особенности:
1. задача оптимизации интерпретируется как пошаговый процесс управления
2. Целевая функция обладает свойством аддитивности, т.е она равна сумме целевых функций каждого шага
3. Выбор управления на k-м шаге зависит только от состояния системы к этому шагу и не влияет на предшествующие шаги (отсутствие обратной связи).
4. На каждом шаге управление Xn зависит от конечного числа параметров.
В результате управления система (объект управления) S переводится из начального состояния S0 в конечное S^ . Управление можно разбить на n шагов, т.е. решение принимается последовательно на каждом шаге, а управление, переводящее систему из начального состояния в конечное, представляет собой совокупность n пошаговых управлений.
Пусть X (x1,x2,…xn) – управление, переводящее систему из начального состояния в конечное. Обозначая через Sk состояние системы после k-го шага управления, получаем последовательность состояний S0, S1,…, Sk-1, Sk,…,Sn-1,Sn=S^, изображенную на рисунке
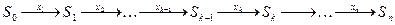
Показатель эффективности, рассматриваемый управляемой операции – целевая функция – зависит от начального состояния и управления Z=F(S0,X).
Существует много способов решения подобных задач, зависящих от вида функций, ограничений, размерности и о которых мы говорили в предыдущих разделах курса (2, 3 и 4). Однако можно использовать вычислительную схему ДП, которая окажется безразличной к способам задания функций и ограничений. Эта схема связана с принципом оптимальности и использует рекуррентные соотношения.
| <== предыдущая страница | | | следующая страница ==> |
| Условие Куна – Таккера | | | Принцип оптимальности и уравнения Беллмана |
Дата добавления: 2015-07-26; просмотров: 161; Нарушение авторских прав

Мы поможем в написании ваших работ!