Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
ГЛОБАЛЬНЫЕ ВЫЧИСЛИТЕЛЬНЫЕ ЗАДАЧИ
1. Исследования в области метеорологии.
2. Исследование структуры динамических и газодинамических неровностей с целью создания сложных аэродинамических комплексов.
3. Изучение свойств вещества в интересах атомной энергетики.
4. Структурное исследование человеческих генов.
5. Молекулярное конструирование лекарств.
6. Проектирование сверхсложных радиометрических комплексов.
Для решения поставленных задач требуется производительность 1012 – 1013 операций в секунду, объем оперативной памяти 1012 – 1015 бит. Эти условия могут быть достигнуты за счет:
- схемотехнических решений,
- распараллеливования вычислительных процессов.
Задача распараллеливования на математическом уровне решена и сводится к решению задач математической физики, то есть к решению задач матрично-векторного типа. Векторно-матричные системы обладают высокой степенью параллелизма, так например перемножение матриц 2-го порядка ранга 100 имеет уровень параллелизма 106
Для решения сложных задач наиболее приемлемы:
1. кластерные архитектуры,
2. многопроцессорные комплексы с общей памятью,
3. машины потоков данных (data flow);
4. платы, которые содержат полностью функциональный ассоциативный процессор для реализации памяти пакетов.
Институт проблем информатики РАН по аналогии с израильской системой создал 128000 72-разрядных слов ассоциативной памяти.
Общая архитектура такой системы:
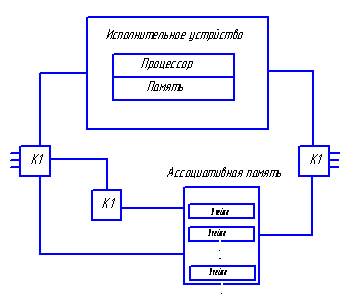
Передача пакетов (ячеек) выполняется независимо по индивидуальным каналам связи. Выходящие из исполнительного устройства (ИУ) данные содержат указатели на операторы, которые должны быть выполнены. Ассоциативная память (АП) объединяет данные, относящиеся к одной команде. Если парного данного в АП нет, то происходит его запись в свободное место. Если есть парные данные, то происходит его считывание из АП и формирование пары данных, которая направляется к одному ИУ, эти данные стираются из памяти. В качестве ИУ используются обычные микропроцессоры.
Основные проблемы, возникающие при организации системы DataFlow:
1. так как для большого числа команд используются одни и те же ресурсы, то используется сверхмультипараллелизм. Каждому запросу ставится в соответствие свой цвет и можно будет определить, какой запрос обрабатывается. Реализуется виртуальная адресация в адресном пространстве.
2. совместный доступ к АП.
Применение АП помогает в решении следующих задач:
- для нескольких процессоров решается проблема обработки массивов, содержащих общие данные для нескольких параллельных процессов;
- проблема стирания и освобождения памяти.
Особенности реализации DataFlow.
1. На аппаратном уровне реализуется сверхпараллелизм.
2. Производительность 1011 – 1013 операций в секунду.
3. Программист исключается из распределения ресурсов, которые выделяются автоматически.
4. Обеспечивается высокая технологичность за счет идентичности модулей.
5. Используется принцип конвейеризации, который обеспечивает отсутствие задержек в логических схемах, то есть скалярные операции выполняются на уровне параллельных вычислений.
6. В АП возможна непосредственная работа с адресами за счет чего процессор может работать в реальном масштабе времени.
Недостаток DataFlow – производительность АП пропорциональна объему. Для устранения используется модульный принцип.
В системе используются два коммутатора:
К1 – распределяет выходящие из АП пары операндов по свободным ИУ,
К2 – распределяет выходящие из ИУ данные по АП.
Если имеется N ИУ и М модулей АП, то К1 и К2 являются матрицами N×M.
Буферная память (БП) используется для сглаживания неровностей потоков данных.
GRID – ТЕХНОЛОГИИ
Суть Grid-технологии – это объединения в сеть различных компьютеров в сеть для решения общей задачи.
Для решения можно использовать:
1. мощные системы – Cray C90, HP Superdone, Cray T3D-T3E, на основе которых можно создать сложные кластерные системы,
2. системы DataFlow (можно объединять с кластерами),
3. использование вычислительных систем + сетевые технологии (на пример, проект Seti www.cs.wisc.edu),
4. объединение пользователей (Internet, www.mersenne.org).
Вычислительные системы с распределенной памятью. Идея построения вычислительных систем с распределенной памятью заключается в том, что несколько вычислительных устройств объединяются с помощью коммуникационной среды. Каждый вычислительный узел имеет один или несколько процессоров.
В последнее время используются ЭВМ, которые имеют собственные внешние устройства. Коммуникационная среда может специально проектироваться для вычислительной системы или быть стандартной сетью на рынке. Преимущества – пользователь или покупатель может достаточно точно подобрать себе конфигурацию, исходя из бюджета и своих потребностей. Соотношение производительность цена гораздо больше, чем у других типов систем. Возможность неограниченного увеличения числа процессоров позволяет увеличить производительность процесса вычислений.
ОСОБЕННОСТИ ПЕРЕХОДА К ПАРАЛЛЕЛЬНЫМ ВЫЧИСЛЕНИЯМ
1. Необходимость выделения последовательных участков, которые должны выполняться в псевдопараллельном режиме или не могут выполняться при определенных ситуациях: доступ к ресурсам, синхронизация процессов и потоков и т.д.
2. Необходимость разработки параллельных компиляторов.
3. Разработка новых параллельных методов решения задач.
4. Разработка программ – отладчиков, которые будут ориентированы на параллельные языки программирования.
5. Разработка стандартов для реализации на многоядерных вычислительных системах:
- использование технологии MPI (обмен сообщениями при реализации параллельных задач),
- OpenMp (на основе разделяемой памяти),
- POSIX (поддерживает параллельные вычисления на основе обмена сообщениями разделенной памяти совместно).
6. Повышение интеллектуальности управления вычислениями.
Для уменьшения разрыва между пиковой производительностью и той, которой реально достигается, требуется аппаратно-программная поддержка параллельных вычислений:
- разработка специализированных процессоров,
- VLIW-архитектура: на каждом шаге исполнения инструкции реализуется сразу несколько операций, т.е. модернизация архитектуры самого процессора,
- конкретная реализация параллельных процессоров с общей и разделенной памятью,
- транзакционная память – это принцип обмена данными с оперативной памятью, служит для автоматизации параллельного выполнения команд с соблюдением принципов: неделимости (транзакция единое целое, если выполнена только часть – то она отклоняется), согласованности (транзакция не нарушает логику и отношения между данными), изолированности (результаты транзакций не зависят от предыдущих и последующих), устойчивости (после своего завершения транзакции сохраняются в системе, происходит фиксация). Реализация транзакционной памяти: программная, аппаратная, комбинированная. Имеет место сходство с методом коллективного доступа с опознаванием несущей и обнаружением коллизий – CSMA/CD. Если в процессе выполнения транзакций возник конфликт, то происходит откат назад.
- многоядерные процессоры и закон возрастающей сложности – смещение сложности из простых процессоров в память и системная сложность постоянно возрастает, несмотря на упрощение компонентов.
Существует два основных момента организации параллельных вычислений:
- многоядерность,
- многопоточность, обеспечивает масштабируемость при загрузке большого числа ядер и потоков.
Sun Microsystems – Sun Ultra Spark
8 ядер, каждое ядро – 4 потока, максимальная частота 1,2ГГц – 72Вт.
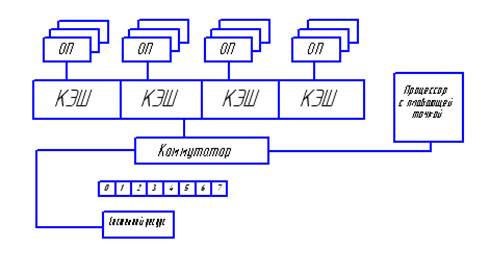
Недостатки:
- один блок с плавающей запятой,
- отсутствие механизма когерентности КЭШа.
Решаемые задачи – хорошо распараллеленные приложения, не требующие высокой производительности при операциях с плавающей запятой.
Niagara II
8 ядер, 8 потоков, каждое ядро имеет свой блок с плавающей запятой, реализован механизм поддержки когерентности КЭШа.
Rock – 2008г.
16 ядер по 2 потока = 32 потока
16 блоков с плавающей запятой и обработкой графикой (FGU)
«аппаратные скауты» - для предварительного просмотра команд на 300-700 циклов вперед.
МНОГОПОТОЧНАЯ МАСШТАБИРУЕМОСТЬ
Существует два способа масштабируемости адресов: горизонтальный и вертикальный.
Вертикальная масштабируемость:
- использование многопроцессорных SMP-серверов, один экземпляр ОС, память, ввод/вывод, один корпус,
- общее межсоединение обладает низкой латентностью, высокой пропускной способностью,
- ресурсы добавляются с помощью увеличения количества плат в сервере.
Горизонтальная масштабируемость:
- объединение нескольких серверов через сеть (кластеризация),
- соединение использует стандартные сетевые адаптеры,
- ресурсы – внутри узлов.
Новый подход: совмещение мощности вертикальной архитектуры с высоким показателем доступности сервисов горизонтальных серверов, возможность выбора не только процессоров, но и ядер.
Перспективы развития.
1. многоядерные и многопоточные решения в системы распределенной информации,
2. продолжение развития классических подходов,
3. альтернативные технологии: ДНК-компьютеры, квантовые компьютеры.
ВЫЧИСЛИТЕЛЬНЫЕ СИСТЕМЫ С РАСПРЕДЕЛЕННОЙ ПАМЯТЬЮ
Вычислительные системы с распределенной памятью – это системы, которые содержат несколько вычислительных узлов, соединенных некоторой коммуникационной средой. При этом каждый процессор имеет свою локальную память и может соединяться с другими процессорами, образуя кластер.
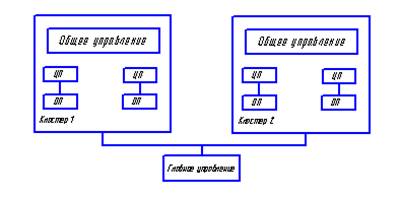
Основные достоинства системы:
- пользователь может достаточно точно подобрать себе конфигурацию, исходя из соответствующих требований,
- соотношение производительность/цена значительно меньше, чем у других систем,
- для каждой конкретной решаемой задачи можно подобрать свою топологию объединений кластеров (двумерная решетка – Intel, иерархические компьютеры – IBM и др.)
Пример реализации кластерной системы:

В каждом узле – процессор, количество узлов от 256 до 1024 и 2048. Передача информации осуществляется по трем направлениям X,Y,Z. Быстродействие зависит от того, как передается информация.
Для передачи информации между двумя процессорами существуют специальные маршрутизаторы, которые обеспечивают оптимизацию времени передачи информации между двумя узлами.
Основные достоинства:
1. гибкая конфигурация,
2. возможность передачи информации по нескольким направлениям одновременно,
3. возможность прокладки альтернативного маршрута, если произошел сбой при передаче информации,
4. возможность быстрой передачи по граничным узлам,
5. возможность организации транзита при передаче данных,
6. каждый процессор может иметь свою память, которую разделяют остальные.
В системах с распределенной памятью для повышения скорости управления и передачи информации используется барьерная синхронизация, что позволяет значительно увеличить качество обслуживания.

РАСШИРЕНИЕ СИСТЕМ С РАСПРЕДЕЛЕННОЙ ПАМЯТЬЮ ДО КЛАСТЕРНЫХ АРХИТЕКТУР
Основная предпосылка появления кластеров – это появление дешевых микропроцессорных элементов на рынке коммуникационных средств и развитие сетевых технологий.
Кластер – это совокупность компьютеров, объединенных в рамках некоторой сети для решения одной задачи.
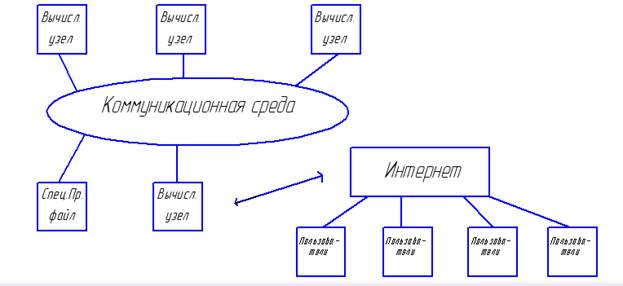
Вычислительный узел может работать под управлением собственной ОС. При этом можно варьировать как количество узлов, так и их мощностью. Это в свою очередь способствует созданию неоднородных кластеров.
Примеры кластеров.
The HIVE {NASA} – Highly-parallel integrated Virtual Environment.
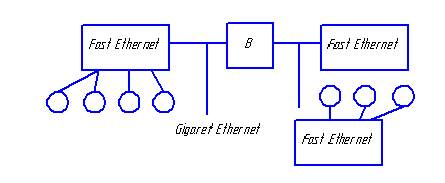
МВС-1000М (Россия, разработан академиком Левиным)
Производительность – 1 терафлокс. Имеется 6 базовых блоков по 64 двухпроцессорных модуля, процессор – «Альфа».
www.jscc.ru
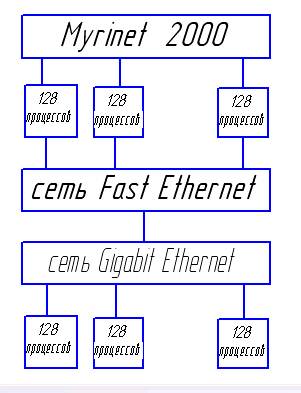
Всего 768 процессоров. Все процессоры связаны между собой двумя сетями. Сеть Myrinet используется для обмена данными в процессе вычисления, FastEthernet используется ОС для выполнения сервисных функций.
Кэш 2-го уровня – 4Мбайта. Пропускная способность каналов – 110-170 Мбайт/сек.
www.parallel.ru
Основные параметры, которыми характеризуются кластерные системы: стоимость, производительность, масштабируемость (возможность создавать различные системы).
Основные недостатки кластерных архитектур:
1. распределенная память, следовательно, задержки в пересылке сообщений определяются скоростью передачи данных,
2. задержка при начальной инициализации – латентность,
3. необходимость синхронизации вычислений при решении одной задачи на нескольких процессорах (системах),
4. необходимость максимальной загрузки модулей кластерных систем,
5. трудность определения оптимального режима работы системы при одновременном решении многих задач.
ТИПЫ ТЕСТОВ ДЛЯ ОЦЕНКИ ПРОИЗВОДИТЕЛЬНОСТИ ВЫЧИСЛИТЕЛЬНЫХ СИСТЕМ
Реальная производительность любой вычислительной системы отличается от пиковой, которая может быть достигнута. Для оценки такой производительности разработана совокупность тестов, по которым оцениваются характеристики MIPS(миллион операций в секунду) и FLOPS (для задач с плавающей запятой).
Типы тестов.
1. Стандарт LINPACK – решение задач линейных алгебраических уравнений с выбором главного элемента в строке. Существует три варианта этого теста.
- система с матрицей 100×100
- система с матрицей 1000×1000 (т.к. сейчас матрица 100×100 может вместиться в кэш).Допускается возможность изменения в текс программы и метод решения.
- с появлением процессоров типа MPP (многопроцессорные системы) размер матрицы 1000×1000 занимает 0,01-0,001% оперативной памяти компьютера, поэтому необходимо иметь другие тесты. Для современных компьютеров при тестировании используются матрицы, размерность > 1 млн.
Для систем с распределенной памятью используется High Performance LINPACK (HPL). Для оценки производительности используются две характеристики: пиковая производительность Rpeak и максимальная производительность Rmax. Rmax=50-70% Rpeak.
N1/2 – определяет на матрице какого размера из серии LINPACK достигается половина Rmax.
Основные недостатки:
- не запрашивается ввод/вывод,
- отношение числа выполненных операций к объему данных высоко,
- имеет место регулярность структуры данных и вычислений,
- малый объем передачи данных между процессором и другими устройствами.
Имеется связь между законом Мура и LINPACK.
2. Стандарт STREAM – содержит 4 цикла, работающих с очень длинными векторами. Основное назначение – это учет сбалансированности загрузки и скорости работы процессора при взаимодействии с памятью.
Ключевые операции:
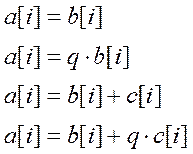
Размеры массивов подбираются таким образом, чтобы они не попали в кэш. Отсутствует возможность повторного исполнения программ.
3. Набор взаимодополняющих тестов – 24 Ливерморских теста (LFK).
В состав вошли ядра прикладных программ, созданных в Ливерморской национальной лаборатории. Используются в основном для оценки возможностей интеллектуальных компьютеров. Тесты являются короткими и используются указания для компиляторов.
4. Тест PERFECT (Performance Evaluation for Cost Transformation)
Содержит 13 различных программ, написанных на Fortran 77. Все программы являются реальными приложениями из различных областей науки и бизнеса. Используется параллельный язык PVM. Примеры программ: прогноз погоды, операции на бирже и т.д.
5. Тест NPB (NAS Parallel Benchmarks) – один из наилучших тестов, разработанных для параллельных систем.
В него входят 2 группы тестов, отражающих различные стороны реальных программ вычислительной гидродинамики.
6. Тест SPEC (Standard Performance Evaluation Corporation)
Основная цель – разработка тестов для моделирования нагрузок.
Наиболее важные параметры при тестировании
С увеличением числа процессоров на передний план перемещается коммуникационный профиль (взаимодействие программ меду собой):
- длина обрабатываемых сообщений в различные моменты времени,
- интенсивность передачи сообщений,
- пути передачи сообщений между процессорами,
- накладные расходы на организацию взаимодействия,
- масштабируемость коммуникационной структуры программ,
- синхронность и асинхронность передаваемых сообщений.
Классификация тестов по применению
1. Вычислительные тесты – оценивают общую производительность системы.
2. Тесты для оценки скорости работы процессора в качестве WEB-сервера.
3. Тесты для оценки качества работы почтового сервера.
4. Тесты для оценки графических подсистем.
5. Тесты для оценки многопроцессорных систем.
6. Тесты для параллельных систем с общей памятью.
Перспективы развития тестирования – необходимо разрабатывать тесты для комплексного тестирования программно-аппаратных средств, необходимо ориентироваться на определенные уровни тестирования:
- базовый уровень программного обеспечения: ОС, компилятор, системы программирования,
- базовый уровень аппаратуры: скорость выполнения элементарных операций, обмен между уровнями иерархии памяти,
- базовый уровень операций ввода/вывода: анализ эффективности различных режимов чтения, записи данных при работе с различными внешними устройствами,
- базовый коммуникационный уровень: определение параметров среды взаимодействия параллельных процессоров,
- коммуникационный уровень приложений: эффективность отображения,
- уровень модельных приложений: выполнение программ различных структур,
- уровень приложений – комплексная проверка характеристик компьютера при выполнении реальных программ.
БОЛЬШИЕ ЗАДАЧИ И ПАРАЛЛЕЛЬНЫЕ ВЫЧИСЛЕНИЯ
Большие задачи представляют собой важные аспекты развития человечества:
- моделирование климата Земли,
- моделирование термоядерных реакций,
- расшифровка генома человека.
Соответствие выполняемый алгоритм – параллельные системы.
Параллельный алгоритм, определение.
Пусть задан ориентированный ациклический граф, имеющий n вершин, тогда существует некоторое число S≤n, для которого все вершины графа можно пометить одним из индексов 1,2,…S. При этом если дуга идет из вершины i в вершину j, то индекс i считается меньше, чем j (если i→j, то i<j). Таким образом все вершины могут быть распределены по ярусам.
Выберем начальную вершину, ту у которой нет начальных дуг, пометим ее «1». Удалим помеченные вершины и дуги с ними связанные. На следующем шаге выберем вершины, не имеющие предшествующих, и пометим цифрой «2». Удалим помеченные вершины и дуги с ними связанные и т.д. Тогда на каждом шаге будем иметь дело хотя бы с одной вершиной. Полученный в результате граф – строгая параллельная форма.
Любой алгоритм можно представить в виде ярусно-параллельной формы. При этом начальными вершинами являются вершины, у которых нет входящих дуг. Конечные вершины – такие, у которых нет исходящих дуг.
Канонической параллельной формой алгоритма называется такая форма, в которой все нулевые вершины находятся в группе с индексом «1». Ярус – это группа вершин с одинаковым индексом. Число вершин в группе – ширина яруса. Число ярусов в параллельной форме – высота параллельной формы.
Параллельная форма минимальной высоты называется максимальной.
Обобщенная параллельная форма – такая форма, в которой условие (i<j) заменяется на условие (i≤j).
Если известен граф алгоритма и его параллельная форма, то можно понять каков запас параллелизма в алгоритме и как его лучше реализовать на конкретном компьютере.
Все оператор, которые находятся на одном ярусе, можно выполнять параллельно, поэтому запас параллелизма определяется шириной яруса. Чем больше ярусов, тем более трудоемкий алгоритм. Поэтому необходимо уменьшать высоту параллельной формы алгоритма с одновременным увеличением его ширины.
КОНЦЕПЦИЯ НЕОГРАНИЧЕННОГО ПАРАЛЛЕЛИЗМА
В 1958 году была разработана система Pilot. Три независимых компьютера объединялись в единую систему для выполнения различных частей одной программы.
В 1962 году создана машина Burroughs D825. Использовались четыре идентичных процессора с общей памятью.
В 1972 году – ILLIAC-IV. Объединялось 256 процессоров.
Считалось, что параллельная система – это система, базирующаяся на методологии большого количества устройств. Чем больше таких устройств – тем больше возможностей решать сложные задачи.
Особенности параллельной формы:
- входные и выходные вершины графа могут отсутствовать,
- граф алгоритма является параметризованным, то есть зависит от данных,
- алгоритм является детерминированным, то есть не имеет условных операторов.
Большое количество устройств порождает идею неограниченного параллелизма, то есть алгоритм может иметь различное количество ярусов, ширина которых соизмерима с числом функциональных устройств. Сложность алгоритма будет определяться его высотой. Для повышения эффективности реализации параллельных алгоритмов, необходимо подбирать схемы их реализации.
Пусть необходимо получить произведение a1 a2 a3 a4 a5 a6 a7 a8
| Ярус | a1 a2 a3 a4 a5 a6 a7 | Ширина = 1 Высота = 7 Сложность =7 |
| (a1 a2 ) | ||
| (a1 a2) a3 | ||
| (a1 a2 a3 ) a4 | ||
| (a1 a2 a3 a4 ) a5 | ||
| (a1 a2 a3 a4 a5 ) a6 | ||
| (a1 a2 a3 a4 a5 a6 ) a7 | ||
| (a1 a2 a3 a4 a5 a6 a7) а8 |
Метод сдваивания
| Ярус | a1 a2 a3 a4 a5 a6 a7 | Ширина = 4 Высота = 3 Сложность =3 |
| (a1 a2 ) (a3 a4) (a5 a6) ( a7 а8) | ||
| (a1 a2 a3 a4) (a5 a6 a7 а8) | ||
| (a1 a2 a3 a4 a5 a6 a7 а8) |
При увеличении N эффективность алгоритма сдваивания повышается и эффективность будет равна log2N.
В общем случае, если высота алгоритма S, то S≥logpN, где р – это число аргументов каждой операции.
ВЫЯВЛЕНИЕ ВНУТРЕННЕГО ПАРАЛЛЕЛИЗМА В ЗАДАЧАХ
Внутренний параллелизм определяется шириной ярусов.
Пусть перемножаются 2 матрицы В и С.
А = В 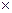 С,
С,
тогда 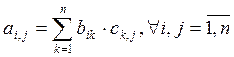 (*)
(*)
Если рассмотреть (*), то можно заметить, что порядок суммирования строго не определен. Поэтому можно рассматривать
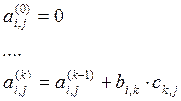
Для матриц 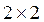 :
:
Построим диаграмму
ЯРУСА ОБОБЩЕННЫХ ПАРАЛЛЕЛЬНЫХ ФОРМ
Кроме строгой параллельной формы с горизонтальными ярусами существуют различные обобщенные формы с наклонными ярусами.
Пусть существует решетка процессоров:
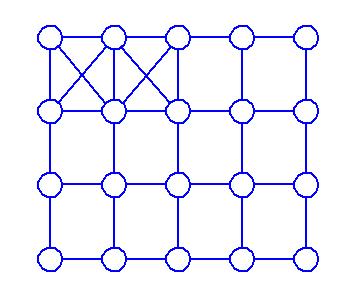
Из решетки процессоров можно выбрать некоторое подмножество процессоров, с помощью которых можно организовать различные ярусы, связанные между собой через определенные типы процессоров. При этом можно одновременно выполнять большое число однотипных операций.
ТЕХНОЛОГИИ ПАРАЛЛЕЛЬНОГО ПРОГРАММИРОВАНИЯ
Попытки создания технологии параллельного программирования наблюдались еще в 60-е годы XX века. Известны параллельные языки ADA, OCCAM и другие. Но несмотря на наличие параллельных архитектур последовательность выполнения команд оставалась той же. Начало создания технологии параллельного программирования в 90-е годы ХХ века. Сегодня существует более 100 технологий, среди них такие как НОРМА, Linda, Occam, OpenMP, DVM и др.
Хотя и наблюдалось создание таких технологий, но возникали определенные трудности в реализации. Ни одна из технологий не гарантирует получение высокой эффективности без дополнительных сведений от программиста.
Требования для использования параллельных технологий:
1. найти в программе ветви, которые должны выполняться параллельно,
2. распределить данные по нескольким локальным памятям,
3. согласовать распределенные данные с параллельностью вычислений.
Трудности реализации параллельных программ:
· использование традиционных компиляторов;
· зависимость между итерациями при выполнении программ.
Одной из возможностей повышения эффективности реализации таких программ является обеспечение возможности формирования подсказок компиляторам о том, какие ветви следует выполнять параллельно. Компилятор должен уметь анализировать цепочки вызовов. Для реализации взаимодействия между различными частями программы необходимы специальные средства, которые реализуются в виде подсказок компилятору:
1. специальные директивы, которые можно указать в комментариях,
2. новые конструкции, то есть дополнительные служебные функции.
В рамках последовательных секции выполняются отдельные составляющие программ, нити выполняются параллельно. Одна и та же программа может быть выполнена как последовательно, так и параллельно (с учетом комментариев). Общие переменные используемые в программе всегда существуют в одном экземпляре. При этом переменные, используемые в отдельных секциях, могут быть локальными или разделяемыми.
Технология OpenMP ориентирована на системы с общей памятью SMP. За основу при реализации берется последовательная программа, а для реализации параллельной программы используются специальные директивы.
Архитектура программы следующая:
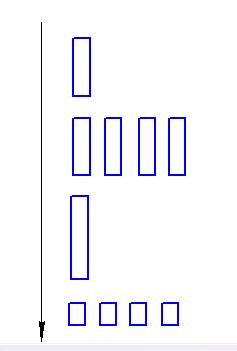
Одна нить (thread) может быть разделена на несколько нитей, которые в последующем снова сводятся к одной. В рамках последовательных секции выполняются отдельные составляющие программ, нити выполняются параллельно. Одна и та же программа может быть выполнена как последовательно, так и параллельно (с учетом комментариев). Общие переменные используемые в программе всегда существуют в одном экземпляре. При этом переменные, используемые в отдельных секциях, могут быть локальными или разделяемыми.
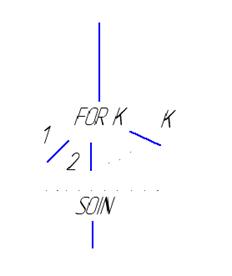
Общая идея технологии OpenMP заключается в том, что некоторые фрагменты текста программы можно объявлять параллельными.
! $OMP
! $OMP PARALLEL
<параллельный код программы>
! $OMP END PARALLEL
Для описания нитей используются директива THREAD.
Особенности OpenMP:
1. параллельные секции могут быть вложенными друг в друга,
2. число нитей параллельных секции можно менять при выполнении определенных условий,
3. возможно распределение работы между нитями (выполнение одного и того же фрагмента программы),
4. возможно распределение итераций по нитям с помощью директивы Шедьюла,
5. возможна организация параллелизма на уровне независимых фрагментов,
6. существуют различные типы переменных, которые могут быть в одном случае разделяемыми, а в другом – локальными.
Достоинства OpenMP:
1. пользователь может работать с единым текстом, как для последовательного, так и для параллельного выполнения программы,
2. компилятор последовательной машины не замечает директивы, так как они написаны в комментариях,
3. для специальных функции и переменных придуманы заглушки,
4. возможность постепенного распараллеливания программы и добавления новых директив, что упрощает программирование и отладку.
Технология DVM (Develop Virtual Machine).
www.keldysh.ru/dvm
DVM содержит 5 основных компонентов:
· компилятор
· система поддержки выполнения параллельных программ
· отладчик параллельных программ
· анализатор эффективности программ
· предсказатель производительности.
Основные принципы:
· высокоуровневая модель выполнения программы
· директивы или спецификации должны быть понятны для обычных компиляторов
· основная работа по реализации модели должна быть выполнена динамически
Директивы формируются в виде строк комментариев
DVM $
! DVM $
C DVM $
DVM – это программа, которая выполняется на виртуальной многопроцессорной системе. Виртуальная машина – это машина с аппаратурой или программным обеспечением, которые предоставляются конкретному пользователю или конкретной программе – MPI-машина. В качестве аппаратуры используются многомерные линейки процессоров, число процессоров и способ их соединения задается непосредственно при запуске программы.
Используются два типа параллелизма:
1. независимые задачи или ветви,
2. в рамках каждой ветви допускаются параллельные циклы.
Все переменные программы размножаются по всем процессорам (на каждом процессоре создается своя копия).
Основные конструкции DVM.
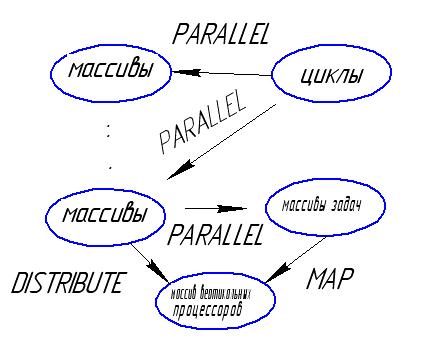
Указанные элементы отображаются на определенную архитектуру.
PARALLEL – распараллеливание
MAP – отображение задач на конкретные массивы
DISTRIBUTE – распределение массивов (определение их типов, отображение)
С DVM $
DISTRIBUTE
<имя массива> формат [onto T(n)]
Поле формат может принимать одно из нескольких значений:
bLock – отображение равными блоками
Onto – отображение массива на ту часть линейки процессоров, но которую отображена n-ая задача вектора задач Т.
Данные, над которыми выполняется операция по технологии DVM, могут быть различных типов:
1. общие данные (данные вычисляются на одних процессорах, а используются на других) – соседние, удаленные, редукционные (глобальные операции),
2. частные данные.
ПРОБЛЕМЫ ПОСТРОЕНИЯ ПАРАЛЛЕЛЬНЫХ СИСТЕМ
1. Трудности микроэлектроники в области создания различных архитектур вычислительных систем, основная задача – подстройка системы под конкретную задачу.
2. Необходимо разрабатывать новые численные методы и новые языки программирования.
3. Необходимость отображения виртуальных вычислительных машин на известные архитектуры.
4. Отсутствуют строгие математические постановки нужных задач, необходимо разработать новые численные методы решения известных задач.
5. Отсутствуют нужные характеристики оценки производительности систем, поэтому невозможно проводить строгие исследования.
6. Необходимо производить исследования в области новых способов вычислений для отображения конкретных процессов.
Основная задача – структура алгоритма.
Эффективность решения параллельных задач определяется двумя факторами:
1. связан с архитектурой машины
2. несколько реализаций алгоритма подходят под одну и туже архитектуру.
СИСТОЛИЧЕСКИЕ МАССИВЫ
Систолические массивы появились в связи с ориентацией на специализацию при решении определенного класса задач.
Особенности систолических архитектур:
1. большое число функциональных устройств,
2. все функциональные устройства являются простым по организации и срабатывают за одно и тоже время,
3. входная и выходная информация соответствует друг другу (если информация на какой-либо систолический элемент не подается, то она должна обрабатываться внутри этого устройства),
4. конструктивно каждое функциональное устройство выполняется в виде четырех- или шестиугольника,
5. входы и выходы каждого систолического устройства выведены на границу многогранников.
Функциональные устройства, определенные таким образом называются систолическими ячейками. Из систолических ячеек можно складывать различные геометрические формы (мозаику), определенным образом соединяя эти элементарные ячейки друг с другом. Таким образом в результате получается специализированная вычислительная система, в которой все ячейки срабатывают синхронно по тактам. Такая система называется систолическим массивом.
Основное ограничение – все систолические ячейки должны быть одинаковыми и располагаться водной плоскости (плоскостные массивы).
Пример.
A,B,C – двумерные ленточные матрицы.
Выполнить D=C+AB
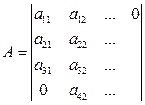
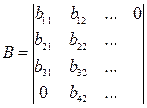
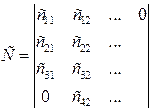
Каждая ячейка может реализовать с+ab и осуществить одновременную передачу в следующую ячейку. Такая функциональность может быть реализована на четырех- или шестиугольной систолической ячейке.
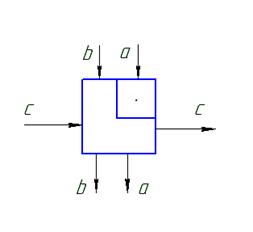
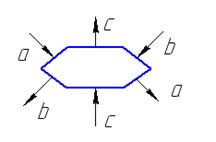 Информация перемещается по направлению стрелок.
Информация перемещается по направлению стрелок. 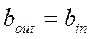
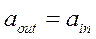 - без изменения передаются на выход в следующую систолическую ячейку. А над операндом с производится операция
- без изменения передаются на выход в следующую систолическую ячейку. А над операндом с производится операция 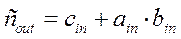 . Все операции выполняются по тактам. Передача информации в следующую ячейку осуществляется синхронно. Если в какой-то момент данные не поступили, то они заполняются нулями.
. Все операции выполняются по тактам. Передача информации в следующую ячейку осуществляется синхронно. Если в какой-то момент данные не поступили, то они заполняются нулями.
Вся плоскость на которой располагаются систолические ячейки покрыта косоугольной решеткой, которые определяют параллельные пути передачи информации.
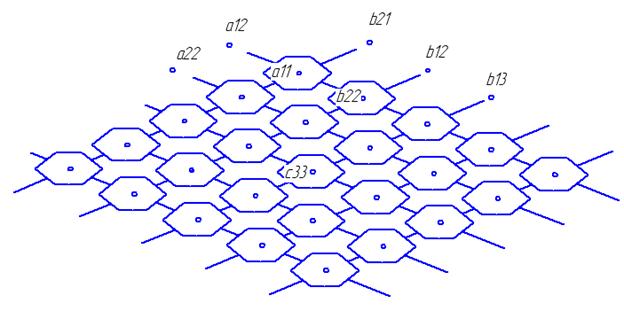
Основная задача, которая должна быть решена это расположение операндов в самих ячейках или на линиях связи этих ячеек таким образом, чтобы время подхода к систолической ячейке, в которой будет произведено действие было синхронизировано. Через каждый такт информация перемещается от ячейки к ячейке. В представленной схеме через каждые 3 такта будут выдаваться элементы матрицы D.
Существуют различные формы систолических массивов. Одни из наиболее распространенных форм реализации: решетка и куб.
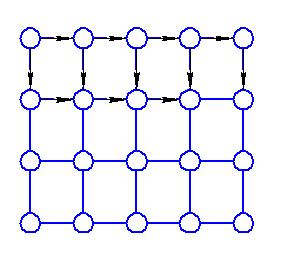
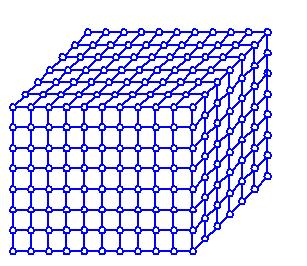
В зависимости от организации транспортной сети могут быть реализованы различные пути вычисления.
На основе исследований, проведенных с различными систолическими массивами, организуют алгебраические вычислители.
Схема алгебраического вычислителя.
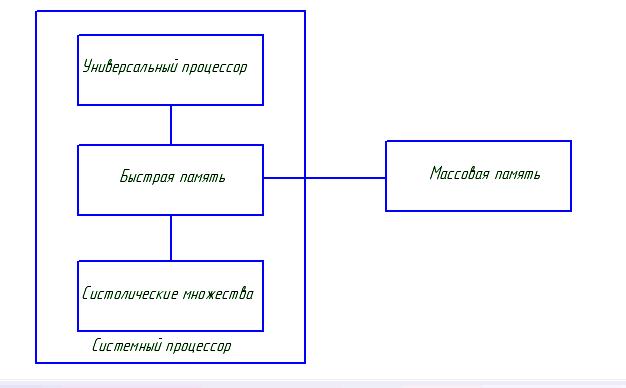
Преимущества:
· упрощаются алгоритмы вычислений
· снижается стоимость
· возрастает функциональность
Основной недостаток систолических массивов заключается в необходимости для каждого алгоритма формировать новую архитектуру, при этом возможно использование большого числа функциональных устройств, которые могут быть не полностью загружены, что снижает производительность системы.
Характеристики вычислительных алгоритмов позволяют наилучшим образом организовать архитектуру вычислительных систем для получения лучшего качества. С другой стороны исследование новых методов вычислительных систем позволяет создать лучшие алгоритмы.
АРХИТЕКТУРЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ ТЕОРЕТИЧЕСКИЕ МОДЕЛИ ПАРАЛЛЕЛЬНЫХ СИСТЕМ
Отрицательным фактором, влияющим на создание параллельных вычислительных систем, является тот факт, что человек думает последовательно.
Ячеечные автоматы фон Неймана.
Ячеечный автомат – это двумерный массив процессоров, каждый из которых общается с четырьмя своими соседями, массив можно продолжить в любом направлении.
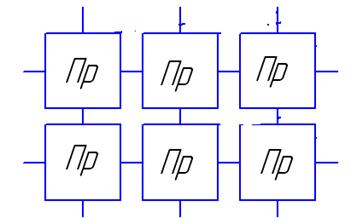
Каждая ячейка представляет собой модуль, каждый модуль имеет 29 состояний функционирования. Эти состояния и правила перехода описаны фон Нейманом. Множество состояний S включает в себя несколько категорий. Выделяется U – универсальное устойчивое состояние, из которого можно перейти в конечное состояние или начать переход в другое состояние. Автомат работает в двоичном коде.
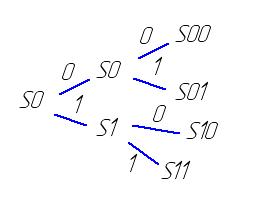
Особенности:
1. каждая ячейка обладает признаком активности, который хоть и не управляет данной ячейкой, но используется для возбуждения следующей.
2. фон Нейман доказал, что ячеечный автомат можно рассматривать как конечный автомат, который состоит из переключателей и линий задержки. Его можно рассматривать как альтернативу машине Тьюринга.
3. с помощью ячеечного автомата можно моделировать различные биологические прототипы, вводя различные типы состояния.
Пространственная машина Унгера
Пространственная машина Унгера – это прототип вычислительной системы, в которой данные могут быть представлены в пространственной форме. Машина обрабатывает данные, представленные в виде массивов на плоскости. Эта машина – прообраз систолических массивов.
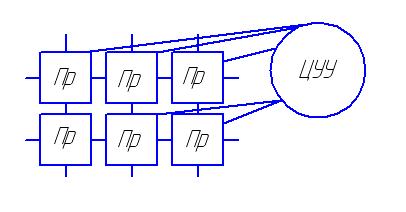
Система – это двумерный процессорный массив, который теоретически является бесконечным. Каждый из процессоров связан со своими четырьмя соседями. Все управляется центральным управляющим устройством (ЦУУ), которое не может обращаться к модулям по отдельности. Одна и та же команда подается сразу на все процессоры. Каждый процессор исполняет команду в соответствии с той программой, которую он выполняет в данный момент. Расшифрованная команда подается как битовый срез, налагающийся на структуру процессора.
Построенная машины Унгера явилась прототипом высокопроизводительных вычислительных систем, которые позволяют:
§ реализовать одну и ту же операцию над многими полями данных,
§ работать как систолические массивы при решении сложных задач.
Машина Холланда.
Машина Холланда – это не ОКМД, которая предназначена для решения следующих задач:
1. одновременное выполнение нескольких различных программ,
2. отработка возможности одновременной передачи информации по разным направлениям.
Данная машина характеризуется тремя особенностями:
1. топологическая структура – это двумерный массив процессорных элементов, а не отдельный процессор обработки массивов данных;
2. подпрограммы распределены между процессорами и обрабатываются одновременно;
3. создавалась как теоретическая модель для исследования работы расширяющихся автоматов.
Каждый процессорный модуль машины Холланда имеет память и соединен с четырьмя соседями. Впервые был предложен принцип активизации процессорного модуля при решении определенной задачи. Каждый процессорный элемент имеет бит активности. Вторая решаемая задача – это прокладка маршрута. При прокладке маршрутов при передаче информации обеспечивает возможность передачи данных за оптимальное время между активными модулями.
В машине Холланда может одновременно существовать несколько активных процессоров. Основой параллельности является определенная организация вычислений – для выполнения любой операции в системе выполняются три фазы.
1. Ввод данных в регистры процессорного элемента.
2. Фаза выборки, то есть выбирается активный процессорный элемент и строится маршрут к процессорному элементу, где хранится операнд.
3. Пересылка операнда, выполнение операции в процессоре.
Построение маршрута является сложным процессом, поэтому в каждом элементарном процессоре должна хранится информация об активности ближайших процессорных элементов.
Для функционирования машины Холланда необходимо разработать алгоритмы определения маршрутов.
1. Был введен бит активности процессорного элемента.
2. Были разработаны алгоритмы прокладки маршрутов для минимизации времени передачи информации между процессорными элементами.
3. Была возможность построения сложных многопроцессорных комплексов, в которых возможна синхронизация работы многих процессоров.
Машина Comfort.
Машина Comfort – это улучшение машины Холланда.

A1 … AN – массив АЛУ.
ПЭ – матрица процессорных элементов.
Каждая линейка процессорных элементов подключается к своему АЛУ.
Цели создания машины Comfort:
§ облегчить программирование,
§ упрощение АЛУ для снижения стоимости,
§ увеличение коэффициента использования аппаратуры,
§ минимальное снижение производительности за счет создания линейки процессорных элементов.
Каждый процессорный элемент содержит память, устройство управления и секцию связи, которая позволяет взаимодействовать этому элементу с ближайшими соседями. Для одновременного использования различных типов АЛУ используется коммутатор.
Особенности машины Comfort.
1. массив ПЭ можно рассматривать как сложное устройство управления,
2. система представляет собой параллельную сеть ПЭ,
3. файлы определения последовательности команд и выполнения операций разнесены (также как и в ОКМД) но при этом определение команд осуществляется для массива ПЭ, а исполнение осуществляется на других блоках, то есть на АЛУ.
Машина Сквайра и Пеле.
Машина Сквайра и Пеле – это матричная система. Они рассматривали эту параллельную вычислительную систему с точки зрения программирования, пренебрегая технологичностью и затратами соответствующего оборудования. Основной критерий – это качество исполнения численных методов и алгоритмов, а не минимизация затрат аппаратуры. Архитектура – n-мерный куб, процессорные модули – это вершины куба, а ребра – это линии связи.
Каждый процессорный модуль содержит АЛУ, схему образования маршрутов, связь с ведущим процессором. Выполнение команды осуществляется в четыре этапа:
§ активизация модулей,
§ образование маршрутов к операндам,
§ выполнение операций,
§ запись резульата.
Особенности машины Сквайра-Пеле:
1. использование большого числа модулей, которые позволяют избежать очереди,
2. использование идентичных модулей,
3. использование топологии n-мерного куба обеспечивает максимальную связность между модулями системы.
Основные проблемы:
1. необходимость сбалансированности памяти и логики на уровне процессорного модуля,
2. необходимость обеспечения гибкой связи множествами различных элементов.
Итеративный ассоциативный компьютер (система IAC).
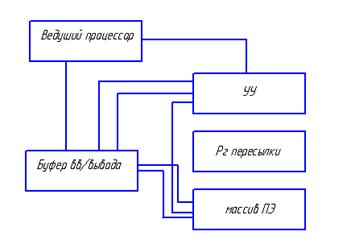
Буфер ввода/вывода осуществляет преобразование информации из последовательного кода в параллельный. Массив процессорных элементов связан через устройство управления с ведущим процессором и каналами ввода/вывода. Регистр пересылки выполняет роль буфера для пересылки операндов в процессорные элементы.
Теоретически построение высокопроизводительных вычислительных систем наметили пути, по которым необходимо следовать для увеличения эффективности работы: сети процессоров, большое количество обрабатывающих устройств, идентичность модулей, внедрение новых топологий связи процессорных элементов в единую систему.
ОТОБРАЖЕНИЕ НЕЙРОННЫХ СЕТЕЙ НА СИСТОЛИЧЕСКИЕ МАССИВЫ
Нейронные сети обладают параллельной архитектурой, поэтому их можно использовать для параллельной обработки информации. Эмуляция нейросетей на обычных микропроцессорах не является эффективной, так как нейросеть обладает очень большим коэффициентом разветвления по выходу. Поэтому в связи с развитием в последнее время систолических архитектур, стало перспективно их использование для реализации нейросетей.
Однослойная нейросеть на систолическом массиве
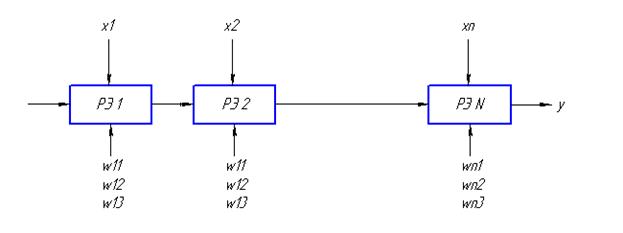
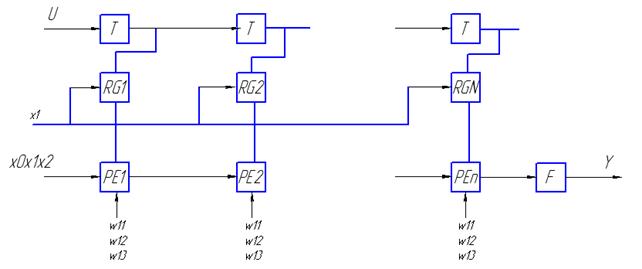
Реализация однослойной нейронной сети на одномерных и двумерных систолических структурах представляет собой совокупность систолических элементов, которые соединяются между собой локальными связями.
Построим граф зависимости выходных значений от входных.
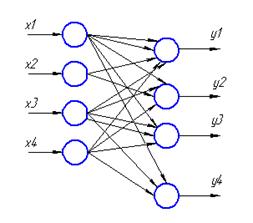
Для реализации этой сети будем использовать множество процессорных элементов PE.
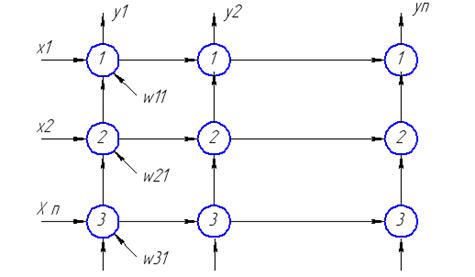
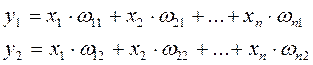
Взвешенная сумма 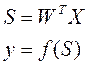
Построим граф зависимости потоков сигналов
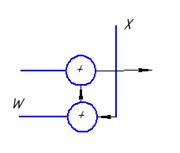
Для получения выхода нейросети необходимо выполнить некоторую последовательность действий:
1. построить графа зависимостей вычислений, характеризующего локальные связи в нейросети,
2. отобразить граф зависимостей в граф потока сигналов, граф зависит от того, какие функциональные элементы PE используются для вычислений,
3. определить функциональную реализацию графа зависимости в некоторую систолическую структуру, для этого необходимо определить временную зависимость между подачей входных сигналов и весовыми коэффициентами.
Для реализации однослойной нейронной сети на систолическом массиве необходимо проводить частичные вычисления с соответствующими задержками.
| № такта | PE1 | PE2 | PE3 |
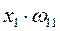
| – | – | |
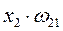
| 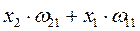
| – | |
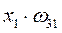
| 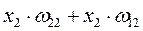
| 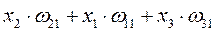
|
Выдача информации из массива осуществляется по тактам.
Использование одной линейки процессоров обладает рядом недостатков, поэтому универсальным является следующий подход: вводятся дополнительные регистры для задержки поступающих сигналов с тем, чтобы сигнал появился в нужный момент времени.
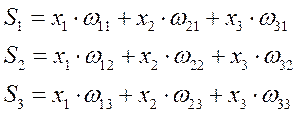
Таким образом, мы получаем все значения последовательно.
Основное достоинство – это простота организации систолического массива, в котором все выходы срабатывают последовательно друг за другом. При этом требуется минимальное количество процессорных элементов. Если обозначить: n – число входов сети, m – число выходов, L – количество обучающих примеров, то общая производительность такого массива
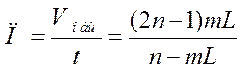 ,
,
где  - общее число операции сложения и умножения,
- общее число операции сложения и умножения,
t – время реализации.
Систолические массивы с разнонаправленными связями
Систолические массивы с разнонаправленными связями используются с целью экономии систолических ячеек. В этой схеме используется принцип двунаправленного распространения сигналов от одного процессорного элемента к другому.
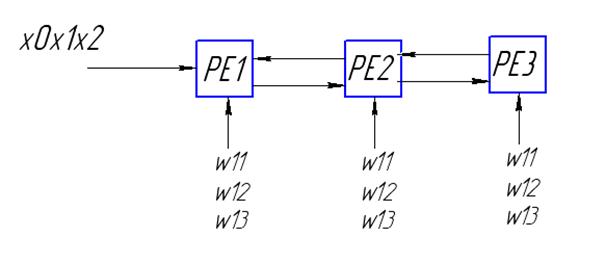
 , где F – функция активации.
, где F – функция активации.
Для получения выхода необходимо заслать в процессорные элементы соответствующие значения весовых коэффициентов. Линейные систолические процессоры могут использоваться для моделирования различных операций линейной алгебры.
Преимущества реализации нейронных сетей на систолических структурах перед обычной реализацией заключаются в простоте и возможности быстрой перестройки на другие операции.
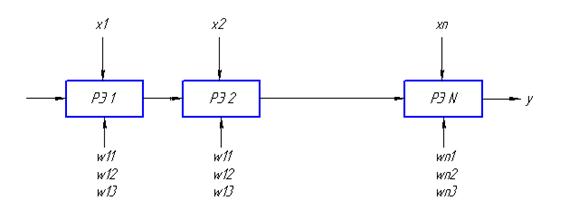
РЕАЛИЗАЦИЯ МНОГОСЛОЙНОЙ НЕЙРОННОЙ СЕТИ НА СИСТОЛИЧЕСКОМ МАССИВЕ
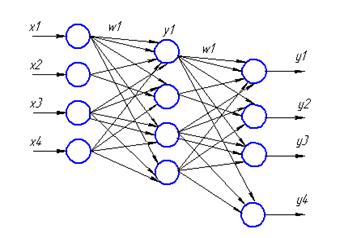
Представленной схеме будет соответствовать следующая схема систолического массива. Процессоры, находящиеся во внутреннем слое и во внешнем, будут отличаться.
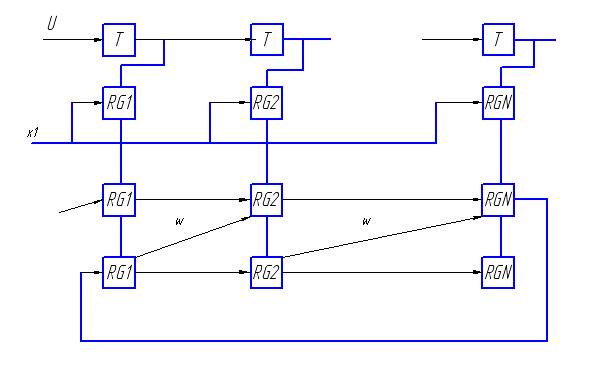
Схема работает по тактам. Сначала подается входной сигнал Х, который распространяется по одной линейке процессоров. На эту линейку подаются весовые коэффициенты W, на выходе по тактам получаются значения промежуточного слоя Y. Нижняя линейка процессоров определяет выход сети – Z. На выходе каждого процессора появляется выходной сигнал.
Основной недостаток такой реализации состоит в том, что сигналы на выходе схемы появляются последовательно, так как время срабатывания различных процессоров отличается. Целесообразно использовать одинаковые процессоры для моделирования многослойной сети.
| <== предыдущая страница | | | следующая страница ==> |
| Покрытие поверхностей рулонными материалами | | | Матричное объединение многослойных НС |
Дата добавления: 2014-08-09; просмотров: 709; Нарушение авторских прав

Мы поможем в написании ваших работ!