Главная страница Случайная лекция

Мы поможем в написании ваших работ!
Порталы:
БиологияВойнаГеографияИнформатикаИскусствоИсторияКультураЛингвистикаМатематикаМедицинаОхрана трудаПолитикаПравоПсихологияРелигияТехникаФизикаФилософияЭкономика

Мы поможем в написании ваших работ!
Динамические информационные структуры
Существуют аналоги между методами структурирования алгоритмов и методами структурирования данных.
Таблица 1. Соответствие между структурами программ и данных
| № | Схема строения | Оператор | Тип данных |
| 1. | Атомарный элемент | Присваивание | Скалярный тип |
| 2. | Перечисление | Составной оператор | Структурный тип |
| 3. | Известное число повторений | Оператор цикла с параметром | Массив |
| 4. | Выбор | Условный оператор | Объединение |
| 5. | Неизвестное число повторений | Оператор цикла с пред/ постусловием | Последовательность или файл |
| 6. | Рекурсия | Оператор функции | Рекурсивный тип данных |
Значения типа данных, который можно назвать рекурсивным, должны содержать одну или более компонент того же типа, что и всё значение, по аналогии с функцией, содержащей один или более вызовов самой себя. Как и в функциях, в таких определениях типов рекурсия может быть прямой и косвенной.
Пример объекта, тип которого можно определить рекурсивно, – арифметическое выражение, встречающееся в языках программирования. Рекурсия отражает возможность вложенности, то есть использования заключенных в скобки подвыражений в качестве операндов в выражении.
Ранее мы рассмотрели объекты базовых типов данных, которые непосредственно поддерживаются языком программирования и включают примитивные числовые и символьные данные, а также массивы, строки и записи. Эти комбинированные (агрегатные) типы данных представляют собой структуры, которые сохраняют данные и предоставляют операции доступа, добавляющие, удаляющие или обновляющие элементы данных.
Далее мы рассмотрим динамические информационные структуры – списки и деревья.
На рис.1 приведена схема иерархии всех структур данных, которые делятся на две основные категории: линейные и нелинейные.
Структура данных, называемая Хэш-таблица, сохраняет данные, связанные с ключом. Ключ трансформируется в целый индекс, используемый для нахождения данных. Ключ не обязательно должен быть целым числом.
Неар - дерево – это особая версия дерева, в котором самый маленький элемент всегда занимает корневой узел.
Граф – структура данных, задающая набор вершин и набор связей, соединяющих вершины.
Списки
Связный список является линейным набором объектов с самоадресацией, называемых узлами (элементами), связанных при помощи указателей. Доступ к списку осуществляется через указатель на первый элемент (голову списка). Последующие узлы доступны через указатели связи, хранящиеся в каждом узле. Данные в списке хранятся динамически, то есть каждый узел создается по мере необходимости. Узлы могут содержать данные любого типа.
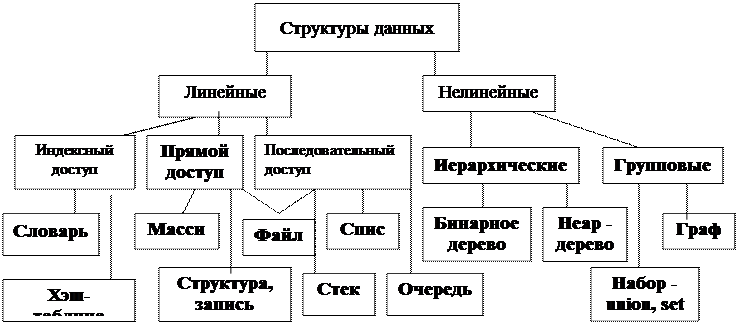
Рис. 1. Иерархия структур данных
Списки данных могут храниться и в массивах, но связные списки предоставляют некоторые преимущества. Размер «обычного» массива не может быть изменен, поскольку он зафиксирован на этапе компиляции. «Обычные» массивы могут переполняться. Связные списки могут переполняться только в том случае, если у системы нет достаточного места для динамического выделения памяти.
Отличия массива и списка:
Связные списки могут сортироваться просто путем вставки каждого нового элемента в соответствующую позицию в списке. При этом существующие элементы списка не надо перемещать.
Операции вставки и удаления в отсортированном массиве могут быть продолжительными по времени, так как все элементы, следующие за вставляемым или удаляемым, должны быть соответствующим образом сдвинуты.
Элементы массива хранятся в памяти непрерывно. Это дает возможность мгновенного доступа к любому элементу массива. Связные списки не предоставляют возможности для такого произвольного (случайного) доступа к своим элементам.
Узлы связных списков обычно физически не хранятся в памяти по соседству друг с другом. Связные списки способствуют экономному использованию ресурсов памяти. Однако указатели занимают дополнительную память.
Списки можно разделять на одно-, двух- и многосвязные.
Односвязные списки дают возможность просмотра в одном направлении. Двусвязные списки являются более универсальными.
Стек является частным случаем связанного списка. Новые узлы могут добавляться в стек и удаляться (выталкиваться) из него только на вершине. Стек является структурой данных типа «последним вошел – первым вышел» (last-in – first-out - LIFO). Элемент связи в последнем узле стека устанавливается на NULL для того, чтобы показать дно стека.
Для запоминания элемента данных в стековой памяти, которая представляет собой бесконечную в одну сторону последовательность слов памяти, элемент заносят в верхнее слово ТОР (ВЕРШИНА), сдвигая тем самым вниз (по одному слову) все другие слова, хранящиеся в стеке. Выбор элементов данных из стека возможен лишь считыванием по одному за раз из слова ТОР, причем все остальные элементы данных сдвигаются вверх. Иногда термин «стек» обозначает стековую память, когда разрешается считывать элементы, находящиеся ниже слова ТОР, но не разрешается изменять их значения или добавлять новые элементы ниже слова ТОР.
У стеков имеется много интересных приложений. «Обратный» порядок размещения объектов в памяти объясняется особенностями работы компилятора. При разборе теста программы компилятор последовательно распознает и помещает в стек имена всех объектов, для которых нужно выделить место в памяти. Затем, после окончания лексического анализа, на этапе распределения памяти имена объектов выбираются из стека, и им отводятся смежные последовательно размещенные участки памяти. Так как порядок записи в стек обратен порядку чтения (выбора) из стека, то размещение объектов в памяти оказывается обратным по сравнению с их взаимным расположением в определениях текста программы.
При вызове функции, вызываемая функция должна знать, как вернуться в вызывающую функцию; в этом случае адрес возвращения помещается в стек. Если происходит ряд обращений к функциям, то последовательность адресов возвращения помещается в стек для того, чтобы каждая функция могла вернуться в свою вызывающую функцию. Стеки поддерживают как рекурсивные вызовы функций, так и обычные не рекурсивные.
У стеков имеется область памяти, выделяемая для автоматических переменных при каждом обращении к функции. Когда функция возвращает управление в вызывающую функцию, эта область для автоматических переменных указанной функции удаляется из стека и эти переменные более не известны программе.
При вызове функции с переменным списком параметров её параметры помещаются в стек, причем порядок их размещения в стеке зависит от реализации компилятора. Более того, в компиляторах имеются опции, позволяющие изменять порядок помещения значений параметров в стек. Стандартная для языка С++ последовательность размещения параметров в стеке предполагает, что первым обрабатывается и помещается в стек последний из параметров функции. При этом у него оказывается максимальный адрес. Именно поэтому для перехода от одного параметра к другому указатель заданного типа увеличивается на 1.
Набор функций для работы со стеком:
struct stek
{
char ch;
struct stek *next;
};
1. Функция помещения значения в стек
void Push (char c, stek **top)
{
stek *q = new stek;
q -> ch = c;
q -> next = *top;
*top = q;
}
2. Функция извлечения из стека
char Pop (stek **top)
{
char c = (*top) -> ch;
stek *p = *top;
*top = (*top) -> next;
delete p;
return c;
}
3. Функция просмотра содержимого стека.
void Print _Stek (stek *top)
{
stek *p = top;
while (p != NULL)
{ putchar (p -> ch);
p = p -> next;
}
}
Другой стандартной структурой данных является очередь. Узлы очереди удаляются только из головы, а помещаются в очередь только в её хвосте. По этой причине, очередь – это структура данных типа «первым вошел – первым вышел» (first -in – first-out - FIFO).
Представление очереди односвязным списком заключается в следующем:
§ запись в очередь моделируется включением в конец списка. Для того чтобы не просматривать каждый раз весь список, в заголовок списка обычно добавляют указатель на последний элемент списка;
§ извлечение из очереди моделируется удалением из начала списка.
Набор функций для работы с очередью:
struct turn
{
int digit;
struct turn *next;
};
4. Функция включения в очередь.
void Put (int num, turn **first, turn **last)
{
turn *q = new turn;
q -> digit = num;
q -> next = NULL;
(*last) -> next = q;
*last = (*last) -> next;
if ((*first) == NULL) *first = *last = q;
}
5. Функция извлечения из очереди.
int Get (turn **first, turn **last)
{
int num = (*first) -> digit;
turn *p = *first;
*first = (*first) -> next;
if ((*first) == NULL) *last = NULL;
delete p;
return num;
}
6. Функция вывода содержимого очереди.
void Print_Turn (turn *first)
{
turn *p = first;
while ( p != NULL)
{ printf (“\t %d”, p -> digit);
p = p -> next;
}
}
Набор функций для работы с двусвязным циклическим списком:
struct list
{
int value;
struct list *prev,*next;
list (int x, list* l, list* r) // конструктор
{ value = x; prev = l; next = r;}
};
7. Функция включения в список.
void Ins_list (int val, list **head)
{
list *q, *pnt = *head;
q = new list (val, NULL, NULL);
if ((*head) == NULL) // Если список пуст
{ q -> prev = q -> next = (*head) = q; return; }
do // Добавляем в «середину» списка
{ if (q->value <= pnt->value)
{ q -> next = pnt;
q -> prev = pnt -> prev;
pnt -> prev -> next = q;
pnt -> prev = q;
if (pnt == (*head)) (*head) = q;
return;
}
pnt = pnt -> next;
} while (pnt != (*head));
// Добавляем в конец списка
q -> next = pnt;
q -> prev = pnt -> prev;
pnt -> prev -> next = q;
pnt -> prev = q;
}
8. Функция исключения из списка.
void Del_list (int val, list **head)
{
list *pnt = *head;
if ((*head) == NULL) // Если список пуст
{ puts("List empty!"); return; }
do
{ if (val == pnt -> value)
{ pnt -> next -> prev = pnt -> prev;
pnt -> prev -> next = pnt -> next;
if (pnt == (*head)) *head = (*head) -> next;
return;
}
pnt = pnt->next;
} while(pnt != (*head));
}
9. Функция вывода содержимого списка.
void Print_list ( list *head)
{
list *pnt = head;
do
{ printf ("%d ", pnt->value);
pnt = pnt->next;
} while(pnt != head);
}
| <== предыдущая страница | | | следующая страница ==> |
| Структурный объект («Запись») | | | Деревья |
Дата добавления: 2014-11-14; просмотров: 439; Нарушение авторских прав

Мы поможем в написании ваших работ!